Project Overview
This is a project to describe the file formats used in certain games developed by Zipper Interactive™:
- the Recoil™ game (1999)
- the MechWarrior 3™ base game (1999)
- the MechWarrior 3 Pirate's Moon™ expansion (1999)
- the Crimson Skies™ game (2000)
Zipper Interactive™ was trademark or registered trademark of Sony Computer Entertainment America LLC. Other trademarks belong to the respective rightsholders.
The main focus is MechWarrior 3.
This documentation can be used as a whitepaper for a clean room implementation to extract most MechWarrior 3 assets, or for reference for existing projects. Note that this project discusses the file structures, and not necessarily the contents of the files.
Terms and abbreviations
- MW or MW3: MechWarrior 3, usually this means the base game and not the expansion.
- PM: Pirate's Moon, aka. the expansion.
- RC: Recoil.
- CS: Crimson Skies.
License

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Pseudo-code conventions
All data types are little endian, unless noted otherwise. All strings are 8-bit US-ASCII, unless noted otherwise (i.e. a character occupies a byte, but only the lower 7 bits are used, the most significant bit is always zero).
All data types and structures are specified in pseudo-Rust code. If you do not know Rust, it should still be familiar.
Unsigned types are designated with u<bits>:
u8isuint8_torunsigned char/bytein Cu16isuint16_tu32isuint32_tu64isuint64_t
Signed types are designated with i<bits>:
i8isint8_torsigned char/charin Ci16isint16_ti32isint32_ti64isint64_t
Floating point types are designated with f<bits>:
f32is a single-precision IEEE 754 floating point number,floatin Cf64is a double-precision IEEE 754 floating point number,doublein C
Note that for many integer data types, we don't know the exact bit size, or even if they are signed or unsigned, unless e.g. an obviously signed value was observed.
Fixed-length and variable length arrays are designated with [<type>; <length>], where the length may not be a valid Rust definition (for example, if it depends on another field).
Constants are aliases for a certain value that makes it convenient to reference by name. Constants will always have a data type specified.
#![allow(unused)] fn main() { const EXAMPLE: u32 = 1; }
Structures are basically memory views/instructions on how to interpret a block of memory. Assume a C-compatible layout and 32 bit alignment (discussed more shortly). They have a name, and then list fields by name followed by a value. An example:
#![allow(unused)] fn main() { struct Example { foo: u32, bar: [f32; foo - 4], } }
This means read an unsigned integer of 32 bits/4 bytes, and then read foo - 4 32 bits/4 bytes floating point numbers.
For structures where the use of a field isn't known, they will be designated with "unk" and the offset of the field in the structure, e.g. unk08. Because MechWarrior 3 is a 32-bit executable and most likely written in C++ (based on the dependencies), the structures the game actually uses will follow those padding rules. The structures provided will either be already 32-bit aligned, or will have explict padding fields, designated with "pad" and the offset.
Tuples are sequences of types/elements. This is similar to structures, except that the fields aren't named:
#![allow(unused)] fn main() { tuple Example(f32, f32, f32); }
This means a structure of 3 floating point values where the field names/usages aren't considered important. I will try to avoid tuples, but they are occasionally useful. You may always translate tuples into structures by naming the fields.
Enumerations are exclusive values, so only a single value is valid. The enumeration will have a integer type that indicates it's size when read. Zero (0) is not generally a valid value unless explicitly named:
#![allow(unused)] fn main() { enum Example: u16 { A = 1, B = 2, } }
Bitflags are similar to enumerations, but can have multiple values set or unset:
#![allow(unused)] fn main() { bitflags Example: u16 { A = 1 << 0, // 0x1 B = 1 << 1, // 0x2 } }
This means that zero (0) is generally valid (this means all unset). For the example, valid values are:
- 0
- 1 = A
- 2 = B
- 3 = A | B
Bitflags may also contain aliases of common flag combinations.
Introduction
To skip the rambling, go straight to the overview.
MechWarrior 3 history
If you want a more entertaining and complete history, Chase "Scharmers" Dahl has an awesome review called Fifteen Years of Giant Robots (specifically MechWarrior 3). Or if video is your thing, The Examined Life (of Gaming)'s MechWarrior Retrospective series (specifically MechWarrior 3) is slightly crude, but otherwise well researched.
I recommend both, and with reason. It's helpful to understand the development history around MechWarrior 3, which is complicated. And the time-frame allows us to put an upper bound on the hardware, software, and techniques available at the time.
The short version: In what is now typical fashion, MechWarrior 3 isn't the third instalment of the MechWarrior series, but the third generation. It was published in May 1999, with a new engine. It received an expansion pack, Pirate's Moon, and a Gold Edition release in September 1999. Due to the troubled development, the fourth generation released quite quickly afterwards, with MechWarrior 4: Vengeance in late 2000 in North America.
The engine seems to be largely developed by Zipper Interactive. Some people have had success using information in this project for other Zipper games, notably Recoil and Crimson Skies. The reverse was sadly not possible, since to my knowledge, no investigation of those games was published.
Why bother?
MechWarrior 4 certainly offer a more balanced, tactical approach with e.g. weapon hard-points to differentiate chassis. So why this game? In my mind, none of these games came close to the campaign of MechWarrior 3. Future campaigns have you starting off as a scrappy lance, but quickly growing and often being able to pick missions for different factions - which I never ended up caring about. MechWarrior 3 is different. Nothing comes close to having to complete an entire operation that goes wrong from the start, with limited supplies and out-of-date tactical information. Despite the troubled development which can be felt in lacking graphics for the time, barren landscapes, and lance mates you hear over the radio more often than you see them, the story shines. This is why it sticks in my head.
Seems I'm not the only one, as there are hundreds of posts trying to get it to work on modern Windows. The most promising approach is dgVoodoo 2, "a wrapper for old graphics API's for Windows Vista/7/8/10". There are still issues with the physics on today's fast processors though.
There is also a preservation aspect. Video game preservation should be important. After all, video games are the medium that has influenced me and many others the most. Preserving music, film, and television is comparatively simple. The day may come when we can emulate a Window XP PC well, but currently, it's hard to experience MechWarrior 3 at all. Being able to understand the assets is the first step.
As an aside, the German localisation is outstanding. Everything was localised, including the intro cinematic, the mission briefing, and in-game dialog. This was a huge selling point for me at the time (my English wasn't quite as polished yet), along with the kick-ass box art (seriously, that Mad Cat). The German CD cover is also gorgeous. Apparently though, the German version was censored. This rings true, as Germany has always had strict rules for video games certification via the USK and JuSchG. For example, the terrorists in "Command & Conquer: Generals" were replaced by robots. The gibs are quite gruesome when stomping on infantry, and seem largely unnecessary in a 'mech focused game. I will discuss the different versions shortly.
The MechWarrior 3 community
There still exists a modding community, and people still play MW3 online. This sounds ideal. When I reached out a few years ago, there was significant trepidation, since understanding game files could make cheating easier. Initially, I would have loved to build on the work of MW3 legends like Finnegan McCool (whom I didn't know at the time, and may have given me a warm welcome). But this is how it goes. And in retrospect, I think this was a blessing in disguise - I would've never started my project!
In the long run, not putting the information out there only hurts the community. People have to rely on out-of-date tools, into which they have no insight. No new tools can be written, and no progress can be made if the original authors leave. I hope my open approach changes this, and there are still enough people who care. There's a hard-core group out there thanks mainly to AncientxFreako, and it's just so great to be able to revitalise interest for a game I treasure.
Also, thanks to sarna.net for keeping all things BattleTech around in such a wonderfully accessible way (including patches).
MechWarrior 3 versions
Base game
In the US, there seem to have been a few releases: version 1.0, 1.1, 1.2, and Gold Edition. They can all be patched to 1.2. Presumably there was also a 1.1 patch (which I have not been able to find). In a weird quirk, the Gold Edition Readme says it is version 1.2, but it is still missing two multiplayer maps, zbd/c3/readermp3.zbd and zbd/c3/readermp4.zbd. Applying the 1.2 patch will install these.
Localisations and versions:
- English (US): 1.0, 1.1, 1.2, Gold Edition
- German (DE): 1.0, 1.2 patch exists
- French (FR): 1.0, 1.2 patch exists
- Italian (IT): Unconfirmed
- Japanese (JA): 1.2 (メックウォリア3)
- Taiwanese (TW): An extremely believable big box edition exists on eBay, but is horrendously expensive (機甲爭霸戰3, see BattleTech on zh.wikipedia.org or chiuinan.github.io)
- Chinese/Hong Kong: Unconfirmed (Simplified: 机甲战士3, Traditional: 機甲戰士3, see BattleTech on zh.wikipedia.org or chiuinan.github.io)
- English (GB): Unconfirmed if this is different than US, although redumps exist
- Russian (RU): Unconfirmed, possibly a bootleg/fan translation only
Please do reach out if you have a version I'm missing. I would love to confirm the information holds for all versions.
I have installed all versions in a virtual machine, gathered the files, patched the versions to 1.2, and gathered the files again. This has allowed me to find differences, but also check that the structures, value-ranges, and methods should hold.
Expansion
I know a lot less about the Pirate's Moon expansion. For one, I never played it, as it was never released in German.
My focus has also been mainly on the base game, and there's still enough unknown information it that. I also only own a single US version of PM. Still, the code from the base game was easy enough to apply to Pirate's Moon, so some things could be discovered. When Pirate's Moon-specific information is known, it is noted in this project.
System requirements
MechWarrior 3 only runs on Windows, and required DirectX 6.1. It is probably a 32-bit executable, given the time frame. And it was likely programmed in C++, specifically Microsoft Visual C++ based on the dependencies. MechWarrior 3 came on a standard CD-ROM.
| Spec | Minimum | Recommended |
|---|---|---|
| Operating system (OS) | Windows 95 | Windows 98 |
| Processor (CPU) | Intel Pentium 166 MHz | Intel Pentium 200 MHz |
| System memory (RAM) | 32 MB | 64 MB |
| Hard disk drive (HDD) | 240 MB | 390 MB |
| Video card (GPU) | 2 MB of VRAM | 8 MB of VRAM |
DRM
The PC Gaming Wiki claims MechWarrior 3 is protected by Macrovision's SafeDisc DRM. At the time MW3 was released, only SafeDisc version 1 was available. Instructions from CD Media World on how to detect SafeDisc protection:
The following files should exist on every the original CD: 00000001.TMP, CLCD16.DLL, CLCD32.DLL, CLOKSPL.EXE, DPLAYERX.DLL
There is always a GAME.EXE and GAME.ICD file where the .ICD is the original game executable (in encrypted form) and the .EXE is a loader containing a parts of the SafeDisc protection.
(Formatting edited for readability.) The Wine mailing list agrees largely, sometimes SECDRV.SYS and DRVMGT.DLL are also found.
None of the US version I own have any of these files, the German version does though. It is possible the US versions have an earlier variant of SafeDisc copy protection, based on the earlier SafeAudio copy protection It uses weak sectors to detect when a disk has been copied. (For more information, see this CD Freaks/Myce article on SafeDisc 2.)
There are indications something odd is present on US disks. When I list the video directory, the date of the parent directory (..) is always mangled:
Version 1.00 (DE):
04/06/1999 02:25 <DIR> .
04/06/1999 02:25 <DIR> ..
Version 1.00 (US):
12/05/1999 02:18 <DIR> .
The parameter is incorrect.
<0x16>? <DIR> ..
Version 1.1 (US):
09/07/1999 12:01 <DIR> .
The parameter is incorrect.
? <DIR> ..
Version 1.2 (US):
05/10/1999 08:35 <DIR> .
<0x11>? <DIR> ..
SafeDisc itself is a liability, as the driver contains a buffer overflow vulnerability (CVE-2007-5587).
I don't want to comment too much on DRM, although as a customer, it has always been an annoyance and a hindrance for me. It is a concern for any effort legally examining the game. Some countries allow circumventing DRM for abandoned products or legitimate fair use. Some don't. This is why I've approached the project by installing the game, and then working on binary files. No DRM is bypassed.
MechWarrior 3 files overview
Installer
The MW3 installer is quite flexible, allowing selection of only some features to save hard drive space. The components and sub-components listed for a custom installation are:
- Program files
- Codec Files
- AVI files
- Software Render Files
- Low Detail
- Medium Detail
- Best Detail
- 3D Accelerator Files
- 2 MB Card
- 4 MB Card
- 8 MB Card+
- Sound
- High Fidelity
- Low Fidelity
Some files not directly installed that are discussed are ambient tracks and save games.
Please note that while many files have the ending .zbd, this does not mean they are in any way similar. Different .zbd files need to be parsed differently (they aren't even all archive files). It's possible .zbd stands for Zipper Binary Data.
Ambient tracks
The ambient tracks are never installed, and always streamed from the CD.
AVI files
If the AVI/video files are not installed, they will be read from the CD. These are the game intro, and cut scenes/mission briefings.
Sound
The high fidelity and low fidelity options installed soundsH.zbd and soundsL.zbd to the zbd directory, respectively. These are both sound archives. The demo only ships with medium fidelity sounds (soundsM.zbd). Additionally, the 1.2 patch installs some loose .wav files into the zbd directory.
Software render files
The software render files component installs textures for the software rendering to the zbd directory. They are largely campaign-specific.
For low detail c1\texture1.zbd, c2\texture1.zbd, c3\texture1.zbd, c4\texture1.zbd, c4b\texture1.zbd, and t1\texture1.zbd are installed.
For medium detail c1\texture2.zbd, c2\texture2.zbd, c3\texture2.zbd, c4\texture2.zbd, c4b\texture2.zbd, and t1\texture2.zbd are installed.
For best detail c1\texture.zbd, c2\texture.zbd, c3\texture.zbd, c4\texture.zbd, c4b\texture.zbd, and t1\texture.zbd are installed.
In each case, the 'mech textures rmechtexs.zbd are also installed.
All of these files are texture packages. The textures for software rendering are largely palette-based.
3D accelerator files
The 3d accelerator files component installs textures for the hardware rendering to the zbd directory. They are largely campaign-specific.
For 2 MB cards c1\rtexture2.zbd, c2\rtexture2.zbd, c3\rtexture2.zbd, c4\rtexture2.zbd, c4b\rtexture2.zbd, and t1\rtexture2.zbd are installed.
For 4 MB cards c1\rtexture3.zbd, c2\rtexture3.zbd, c3\rtexture3.zbd, c4\rtexture3.zbd, c4b\rtexture3.zbd, and t1\rtexture3.zbd are installed.
For 8 MB+ cards c1\rtexture.zbd, c2\rtexture.zbd, c3\rtexture.zbd, c4\rtexture.zbd, c4b\rtexture.zbd, and t1\rtexture.zbd are installed.
In the 2 MB case, the 'mech textures rmechtex16.zbd are also installed; otherwise, the 'mech textures rmechtex.zbd are also installed.
All of these files are texture packages. The textures for 3d accelerator rendering are not palette-based, but do have a reduced bit depth.
Program files
The program files component installs the following files to the specified install location:
force_eff.ifr: Probably force-feedback effects. I think this was a technology developed by the Immersion Corporation. The file extension.ifrstands for "Immersion Force Resource", which are pre-built effects authored in a tool called Immersion Studio. It's not clear how the game engine used these, and they deserve more investigation.Mech3.exe: The main game engine executable. Not further discussed.Mech3.icd: Only present for the German version, probably related to the SafeDisc DRM. Discussed tangentially in the introduction; otherwise not further discussed.Mech3Msg.dll: A resource dynamic link library (DLL), which contains localised messages. Discussed in message table/translations.MSN Gaming Zone.url: A Windows Internet Shortcut file, presumably to the MSN Gaming Zone, now known as MSN Games. Not further discussed.ReadMe.docorreadme.doc,ReadMe.txtorreadme.txt: The READMEs for the game in both Microsoft Word (.doc) and plain text (.txt) format. Not further discussed.Uninstl.ddlandUninstall.isu: Support files for the InstallShield uninstaller. Not further discussed.
These files are also installed on the system:
arial.ttf,impact.ttf, andlucon.ttf: Font files the game engine needs.IFORCE2.dll: Probably force-feedback effects, seeforce_eff.ifr.MSVCRT.DLL,msvcirt.dll,MSVCRT40.DLL, andMSVCP50.DLL: Support the Microsoft Visual C/C++ Runtime. These could be used to determine which MSVC version was used. Not further discussed.MFC40.DLLandMFC42.DLL: Microsoft Foundation Class Library (MFC) dependencies. Not further discussed.
The codec sub-component also installs Ir50_32.dll. This video codec is relevant for the AVI files.
The program files component also installs all the necessary game files to the zbd directory in the specified install location. These are called database files, and have their own section below.
Database files
Database files are installed by the program files component. There are a lot of data files, and can be grouped into various categories. In general, database files are either:
- global, in the root
zbddirectory - operation or chapter specific. The sub-directories
c1,c2,c3,c4,c4b, andt1seem to correspond to the operations of the campaign.t1for the training operation, andc1toc4for the main campaign's operations/chapters. One oddity isc4b, which is possibly split off because the third and fourth operations (c3/c4) had 6 missions each (instead of four), and there was some kind of game engine limitation - mission specific. Multiplayer or instant action scenarios are also "missions" associated with a specific operation/chapter. These are identified by the file name's suffix, e.g.
m1for mission 1,mp1for multiplayer map 1, andia1for instant action scenario 1.
Texture packages
The rimage.zbd provides globally-used images, such as UI elements, menu backgrounds, and more. This file is a texture package, and can be read in the same way software render files and 3D accelerator files are read.
Reader archives
Reader archives contain game configuration. They can be global (reader.zbd), campaign-specific (c1\reader.zbd, c2\reader.zbd, c3\reader.zbd, c4\reader.zbd, c4b\reader.zbd, t1\reader.zbd), mission-specific (<chapter directory>\readerm*.zbd), multiplayer maps (<chapter directory>\readermp*.zbd), or instant action scenarios (<chapter directory\readeria*.zbd). This is the full list:
reader.zbdc1\reader.zbdc2\reader.zbdc3\reader.zbdc4\reader.zbdc4b\reader.zbdt1\reader.zbdc1\readeria1.zbdc1\readeria2.zbdc1\readeria3.zbdc1\readerm1.zbdc1\readerm2.zbdc1\readerm3.zbdc1\readerm4.zbdc1\readermp1.zbdc1\readermp2.zbdc2\readeria1.zbdc2\readeria2.zbdc2\readeria3.zbdc2\readerm1.zbdc2\readerm2.zbdc2\readerm3.zbdc2\readerm4.zbdc2\readermp1.zbdc2\readermp2.zbdc3\readeria1.zbdc3\readeria2.zbdc3\readeria3.zbdc3\readerm1.zbdc3\readerm2.zbdc3\readerm3.zbdc3\readerm4.zbdc3\readerm5.zbdc3\readerm6.zbdc3\readermp1.zbdc3\readermp2.zbdc4\readeria1.zbdc4\readeria2.zbdc4\readeria3.zbdc4\readerm1.zbdc4\readerm2.zbdc4\readerm3.zbdc4\readermp1.zbdc4\readermp2.zbdc4b\readerm4.zbdc4b\readerm5.zbdc4b\readerm6.zbdt1\readeria1.zbdt1\readerm1.zbdt1\readerm2.zbdt1\readerm3.zbdt1\readerm4.zbdt1\readermp1.zbd
Two more multiplayer maps are provided by the 1.2 patch: c3\readermp3.zbd and c3\readermp4.zbd.
Interpreter scripts
The interpreter scripts (interp.zbd) drive how the game engine loads the game data/worlds.
Mechlib archive
A single mechlib archive is installed, mechlib.zbd. This contains 'mech and mechlib model data.
Motion archive
A single motion archive is installed, motion.zbd. This contains the animation data for 'mech motion (e.g. walking).
Game world data
The game world data is called gamez.zbd, and so also known as GameZ files. Each operation/chapter has its own game world data in the sub-directory:
c1\gamez.zbdc2\gamez.zbdc3\gamez.zbdc4\gamez.zbdc4b\gamez.zbdt1\gamez.zbd
Animation definition archives
While animation definitions are provided in some reader archives, they are also present in a compiled form in animation definition files, called anim.zbd. These correspond to each game world:
c1\anim.zbdc2\anim.zbdc3\anim.zbdc4\anim.zbdc4b\anim.zbdt1\anim.zbd
Save games
TODO
Ambient tracks
Ambient tracks are music tracks, longer than sound effects. There are two 3 minute tracks for the base version of MechWarrior 3, and one 9.5 minute track for the Pirate's Moon expansion. They are never installed, and so must be retrieved from the CD. They are used as background music during missions.
Investigation
When I insert a MechWarrior 3 CD into a Mac, iTunes opens. When I insert a MechWarrior 3 CD into a Windows PC, this message shows:

An enhanced audio CD contains data and audio on the same disk. So the ambient tracks are simply CD audio, which are presumably streamed from the CD during gameplay. A re-implementation should also be able to do this.
There are only two ambient/background tracks, roughly three minutes earch. Using a tool such as ExactAudioCopy (EAC)1, it is possible to copy the audio tracks as Waveform Audio files (WAV, *.wav) where it is legal to do so.
For individuals wanting to enjoy these tracks, it's worth noting these WAV files are rather large. For preservation, a lossless compression like FLAC uses about ~40% of the storage space. Since the tracks slightly differ between the different versions, for general use a lossy format like AAC with a bitrate of 128 kilobytes or above should be plenty. This produces file sizes around 10% of the original.
EAC is Windows only. Options on macOS are RIP, Max, XLD, or iTunes. There are many options on Linux, I suggest Morituri.
In-game use
To my knowledge, the ambient tracks do not play in the menus, only during gameplay. I don't know how the engine uses these tracks:
- Does the engine select a random track, or always starts on the first (audio) track?
- Does the engine loop the tracks once they finish playing, or is there simply slience after a mission time of over six minutes?
Appendix 1: Detailed version comparison
Between the versions, all the tracks had different CRC codes. Another oddity is the fact the tracks aren't in the same order on different versions. I'm unsure why this is. The difference in the audio data could be the result of the manufacturing process. For the German version, it could be due to the SafeDisc DRM (is 2 seconds longer). But they all sound indistinguishable for me, and the waveforms look the same, so it's probably fine.
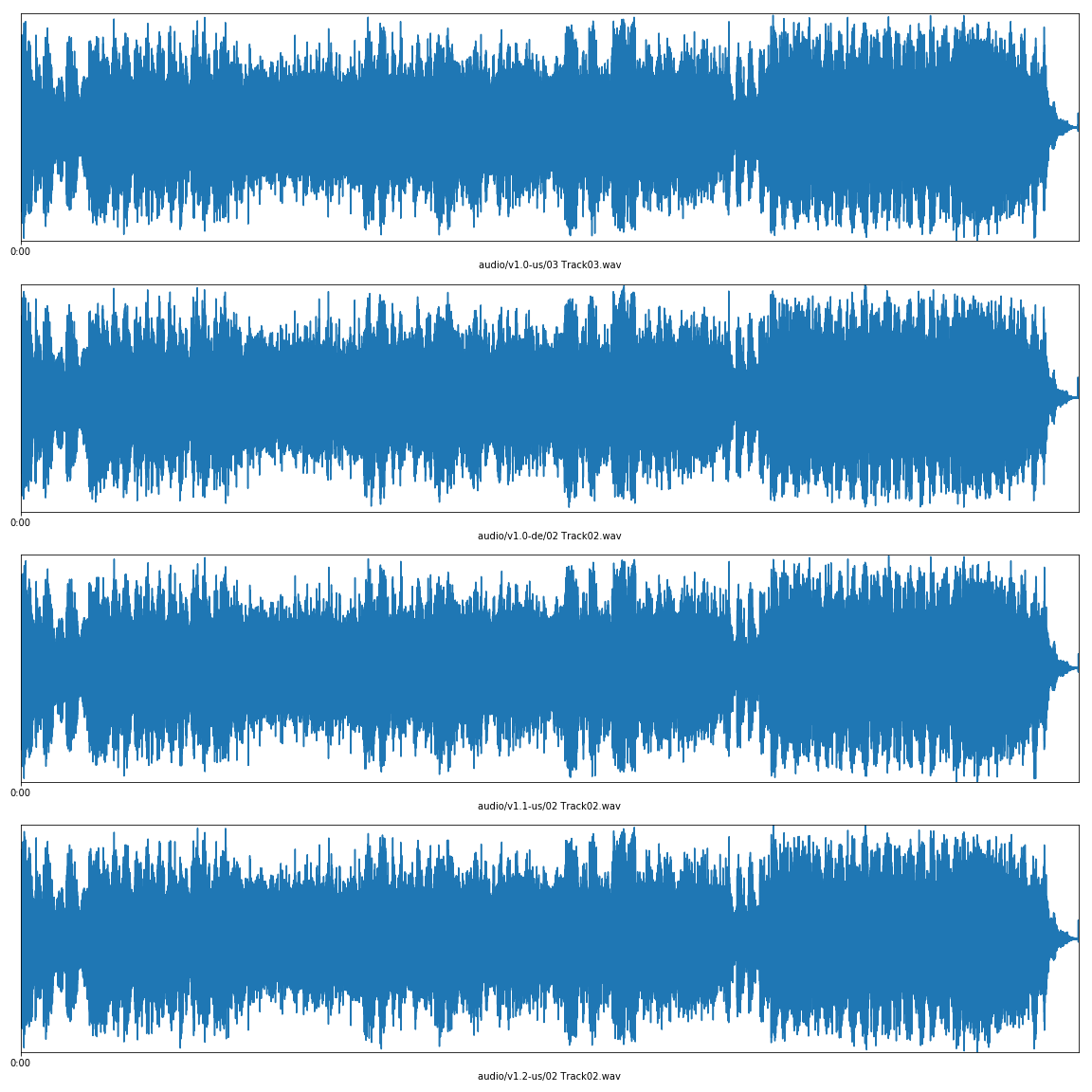
These are the detailed track information of all MechWarrior 3 versions I own:
v1.0 US
| Track | Start | Length | Start sector | End sector | Size | CRC |
|---|---|---|---|---|---|---|
| 1 | 0:00.00 | 59:12.45 | 0 | 266444 | 597.64 MiB | |
| 2 | 59:12.45 | 3:11.69 | 266445 | 280838 | 32.28 MiB | 515BECAE |
| 3 | 62:24.39 | 3:06.06 | 280839 | 294794 | 31.30 MiB | 45D64143 |
CTDB TOCID: hUJiDDh7s2IYPP1GpLfGVYpIWxE-
v1.0 DE
| Track | Start | Length | Start sector | End sector | Size | CRC |
|---|---|---|---|---|---|---|
| 1 | 0:00.00 | 62:48.56 | 0 | 282655 | 634.00 MiB | |
| 2 | 62:48.56 | 3:06.06 | 282656 | 296611 | 31.30 MiB | EDCC302C |
| 3 | 65:54.62 | 3:13.69 | 296612 | 311155 | 32.62 MiB | A262C28B |
CTDB TOCID: vPmoaaMWAdaLNkVSMLqK2HZxmaE-
v1.1 US
| Track | Start | Length | Start sector | End sector | Size | CRC |
|---|---|---|---|---|---|---|
| 1 | 0:00.00 | 59:12.20 | 0 | 266419 | 597.59 MiB | |
| 2 | 59:12.20 | 3:06.06 | 266420 | 280375 | 31.30 MiB | 825686B5 |
| 3 | 62:18.26 | 3:11.69 | 280376 | 294769 | 32.28 MiB | 21627377 |
CTDB TOCID: WJdZLalC42N4VOtU.QQx5GDfvqI-
v1.2 US
| Track | Start | Length | Start sector | End sector | Size | CRC |
|---|---|---|---|---|---|---|
| 1 | 0:00.00 | 59:12.34 | 0 | 266433 | 597.62 MiB | |
| 2 | 59:12.34 | 3:06.06 | 266434 | 280389 | 31.30 MiB | DB5F6872 |
| 3 | 62:18.40 | 3:11.69 | 280390 | 294783 | 32.28 MiB | 61502511 |
CTDB TOCID: WJdZLalC42N4VOtU.QQx5GDfvqI-
v1.2 PM
| Track | Start | Length | Start sector | End sector | Size | CRC |
|---|---|---|---|---|---|---|
| 1 | 0:00.00 | 22:18.11 | 0 | 100360 | ||
| 2 | 22:18.11 | 9:22.61 | 100361 | 142571 | 535BD032 |
CTDB TOCID: Y1qrr8eDEKTsSDhgyfHah6MGKzA-
Appendix 2: How the waveform plots were made
I used SciPy to read WAV file data, and matplotlib to plot them:
import numpy as np
from scipy.io import wavfile
from scipy.signal import resample
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
def time_ticker_format(x, pos=None):
mins, secs = divmod(x, 60)
return "{:.0f}:{:02.0f}".format(abs(mins), secs)
def plot_waveforms(tracks, save_name=None, resample_factor=40):
"""This function makes assumptions about the input data: stereo 44100 Hz 16-bit signed PCM"""
data = []
rates = []
for track in tracks:
rate, stereo = wavfile.read(track, mmap=True)
samples, channels = stereo.shape
assert channels == 2, "expecting stereo"
mono = stereo.mean(1)
# this is to make the data more resonable to plot
resampled = resample(mono, int(np.ceil(mono.size / resample_factor)))
data.append(resampled)
rates.append(rate)
rate = rates[0]
assert all(rate == r for r in rates)
count = len(tracks)
fig, axis = plt.subplots(count, 1, figsize=(16, 4 * count))
for ax, mono, name in zip(axis, data, tracks):
samples = mono.size
length = samples / rate
time = np.linspace(0, length, num=samples)
ax.plot(time, mono)
ax.set_xlim(0, length)
ax.xaxis.set_major_formatter(ticker.FuncFormatter(time_ticker_format))
ax.xaxis.set_major_locator(ticker.MultipleLocator(20))
ax.set_ylim(-(1 << 15), (1 << 15)) # signed 16-bit
ax.yaxis.set_major_locator(ticker.NullLocator())
ax.xaxis.set_label_text(name)
fig.tight_layout()
if save_name:
plt.savefig(save_name)
plt.close(fig)
AVI files
The Mechwarrior 3 intro and campaign videos are found in the video directory on the CD. They can also optionally be installed to the hard drive.
Investigation (MW3)
They are AVI containers (*.avi). The video codec is known from the installation, but we can confirm that and gather more information using ffmpeg, specifically ffprobe. This is for campaign.avi, information on all English video files can be found in the appendix:
Input #0, avi, from 'Campaign.avi':
Duration: 00:03:24.27, start: 0.000000, bitrate: 3320 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 3020 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
The video streams are encoded using Intel's Indeo codec (version 5, FourCC IV50). They are all 640x480 at 15 frames per second, although the bitrates vary from 3020 kb/s to 1260 kb/s. The audio streams are raw pulse-code modulation (PCM) at 22050 Hz, so uncompressed.
For the German version, these have the metadata "Sound Forge 4.0 Audio" attached, which was a German sound editing program, probably used by the localisation team.
These codecs were no doubt chosen because they could be decoded with very little CPU, not because of their quality. This is especially true if they had to be streamed from the CD. Codecs have come far since then, with ubiquitous hardware support. Indeo has at least one vulnerability, meaning the codec is unlikely to be installed on modern systems. Realistically, the best option is to re-encode at least the video using existing software (ffmpeg). Installing the old codec is obviously inadvisable, and reverse engineering the codec is complicated and unnecessary.
The file checksums between the US versions 1.0, 1.1, and 1.2 are exactly the same (on the CD - I don't think the patch affects the video files, simply based on the size, but haven't checked).
Re-encoding
TL;DR:
for f in *.avi
do
ffmpeg \
-i "$f" \
-codec:v "libx264" \
-preset "medium" \
-crf "30" \
-codec:a "aac" \
-b:a "64k" \
"${f%.*}.mp4"
done
To compress the audio, there are several options. If supported, advanced audio coding (ACC) is excellent at low bitrates, and for mainly speech, using 64 kb/s is fine without any concerns of quality loss. The command line options are -codec:a aac -b:a 64k1. AAC is patented and not all game engines support it. This is generally problematic for good audio codecs. A viable alternative is to not alter the audio and just copy it using -codec:a copy, as raw PCM support is ubiquitous.
As mentioned, I definitely wanted to re-encode the video because of known Indeo vulnerabilities. H.264/x264 is widely supported. Quality-wise, it's a bit trickier than the audio, because it's more subjective in comparisons. The original video is highly compressed, with visible compression artefacts - please keep this in mind, the re-encoded file can't be better than the original. So personally, I find the video re-encoded with a low bitrate fine. In fact, choosing a low bitrate smooths some of the original, block-y compression artefacts out (the smoothing could be done via processing at higher bitrates). But you can decide for yourself, in a minute I'll show how to compare the re-encoded to the original. And worst case, files can be re-encoded from the original again.
My recommendation is to use a fairly quick encoding to test things out, and a low quality factor. Something like -codec:v libx264 -preset medium -crf 28. It's worth reading the ffmpeg H.264 encoding guide if you wish to change these parameters. Choose a slower preset should deliver the same quality at a lower bitrate, at expense of encoding time. Choosing a lower crf value will increase the bitrate, which in theory increases quality. Given the source material, that probably won't do much those. Once you're happy with the parameters, I'd suggest using a slower preset for the final encoding, like veryslow, since processing power is cheap and these videos are short and have a tiny resolution (generally, the preset doesn't affect quality very much).
For a container format with maximum compatibility, I've chosen MPEG-4 (*.mp4), although if supported by your use-case, the open standard Matroska (*.mkv) is an excellent choice.
libfdk might be slightly higher in quality, and if your build of ffmpeg was compiled with libfdk support you could try using the libfdk_aac codec. That also enabled the use of variable bit rate. However, I don't think it's worth the effort. The input isn't exactly high quality in the first place, and the built-in AAC encoder is pretty good.
Comparing results
The MPV media player can play two (or more) videos side-by-side, which is great for comparing the encoded video.
mpv --lavfi-complex="[vid1][vid2]hstack[vo]" intro.avi --external-file=intro.mp4
In-game use
The introduction is played when the game is loading. The campaign videos are played when the campaign is started, and between missions.
Appendix 1: Modern codec performance
It's interesting to see just how far codecs have come. For those settings, the average reduction in size is 86% for the US version and almost 89% for the German version!
video/v1.0-us
| Filename | Original | Compressed | Reduction |
|---|---|---|---|
| intro.avi | 78.36 MiB | 5.47 MiB | 93.0% |
| Campaign.avi | 80.85 MiB | 12.45 MiB | 84.6% |
| c1.avi | 14.50 MiB | 1.36 MiB | 90.6% |
| c1m1.avi | 8.75 MiB | 0.97 MiB | 88.9% |
| c1m2.avi | 5.96 MiB | 0.77 MiB | 87.0% |
| c1m3.avi | 5.21 MiB | 0.74 MiB | 85.7% |
| c1m4.avi | 9.17 MiB | 1.16 MiB | 87.4% |
| c2.avi | 10.79 MiB | 1.67 MiB | 84.6% |
| c2m1.avi | 4.77 MiB | 0.65 MiB | 86.4% |
| c2m2.avi | 10.41 MiB | 1.22 MiB | 88.3% |
| c2m3.avi | 6.31 MiB | 0.75 MiB | 88.2% |
| c2m4.avi | 7.68 MiB | 0.79 MiB | 89.7% |
| c3.avi | 5.48 MiB | 1.62 MiB | 70.5% |
| c3m1.avi | 5.93 MiB | 1.06 MiB | 82.1% |
| c3m2.avi | 6.24 MiB | 1.02 MiB | 83.6% |
| c3m4.avi | 7.45 MiB | 1.12 MiB | 84.9% |
| c3m5.avi | 9.49 MiB | 1.08 MiB | 88.6% |
| c3m6.avi | 5.73 MiB | 0.84 MiB | 85.3% |
| c4win.avi | 23.98 MiB | 1.49 MiB | 93.8% |
Average reduction: 86.5%
video/v1.0-de
| Filename | Original | Compressed | Reduction |
|---|---|---|---|
| intro.avi | 76.00 MiB | 5.33 MiB | 93.0% |
| Campaign.avi | 77.76 MiB | 11.35 MiB | 85.4% |
| c1.avi | 13.45 MiB | 1.36 MiB | 89.9% |
| c1m1.avi | 10.88 MiB | 0.97 MiB | 91.1% |
| c1m2.avi | 7.44 MiB | 0.77 MiB | 89.6% |
| c1m3.avi | 6.50 MiB | 0.74 MiB | 88.5% |
| c1m4.avi | 11.38 MiB | 1.16 MiB | 89.8% |
| c2.avi | 13.32 MiB | 1.67 MiB | 87.5% |
| c2m1.avi | 5.95 MiB | 0.65 MiB | 89.1% |
| c2m2.avi | 12.86 MiB | 1.22 MiB | 90.5% |
| c2m3.avi | 7.86 MiB | 0.75 MiB | 90.5% |
| c2m4.avi | 9.46 MiB | 0.79 MiB | 91.6% |
| c3.avi | 6.88 MiB | 1.62 MiB | 76.5% |
| c3m1.avi | 7.38 MiB | 1.06 MiB | 85.6% |
| c3m2.avi | 7.75 MiB | 1.02 MiB | 86.8% |
| c3m4.avi | 9.27 MiB | 1.13 MiB | 87.9% |
| c3m5.avi | 11.80 MiB | 1.08 MiB | 90.9% |
| c3m6.avi | 7.15 MiB | 0.84 MiB | 88.3% |
| c4win.avi | 23.98 MiB | 1.50 MiB | 93.8% |
Average reduction: 88.7%
Appendix 2: English video file information
Input #0, avi, from 'Campaign.avi':
Duration: 00:03:24.27, start: 0.000000, bitrate: 3320 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 3020 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c1.avi':
Duration: 00:00:58.00, start: 0.000000, bitrate: 2096 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1236 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 22050 Hz, 2 channels, s16, 705 kb/s
Input #0, avi, from 'c1m1.avi':
Duration: 00:00:46.00, start: 0.000000, bitrate: 1595 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1275 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c1m2.avi':
Duration: 00:00:31.67, start: 0.000000, bitrate: 1577 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1263 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c1m3.avi':
Duration: 00:00:27.73, start: 0.000000, bitrate: 1577 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1258 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c1m4.avi':
Duration: 00:00:48.33, start: 0.000000, bitrate: 1591 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1268 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c2.avi':
Duration: 00:00:56.67, start: 0.000000, bitrate: 1596 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1265 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c2m1.avi':
Duration: 00:00:25.27, start: 0.000000, bitrate: 1584 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1270 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c2m2.avi':
Duration: 00:00:54.40, start: 0.000000, bitrate: 1605 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1275 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c2m3.avi':
Duration: 00:00:33.33, start: 0.000000, bitrate: 1587 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1270 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c2m4.avi':
Duration: 00:00:39.80, start: 0.000000, bitrate: 1618 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1286 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c3.avi':
Duration: 00:00:29.27, start: 0.000000, bitrate: 1570 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1264 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c3m1.avi':
Duration: 00:00:31.47, start: 0.000000, bitrate: 1579 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1260 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c3m2.avi':
Duration: 00:00:33.20, start: 0.000000, bitrate: 1575 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1252 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c3m4.avi':
Duration: 00:00:39.53, start: 0.000000, bitrate: 1580 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1260 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c3m5.avi':
Duration: 00:00:50.07, start: 0.000000, bitrate: 1590 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1270 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c3m6.avi':
Duration: 00:00:30.40, start: 0.000000, bitrate: 1582 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 1266 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'c4win.avi':
Duration: 00:01:12.20, start: 0.000000, bitrate: 2786 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 2481 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_u8 ([1][0][0][0] / 0x0001), 22050 Hz, 1 channels, u8, 176 kb/s
Input #0, avi, from 'intro.avi':
Duration: 00:03:02.47, start: 0.000000, bitrate: 3602 kb/s
Stream #0:0: Video: indeo5 (IV50 / 0x30355649), yuv410p, 640x480, 2764 kb/s, 15 fps, 15 tbr, 15 tbn, 15 tbc
Stream #0:1: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 22050 Hz, 2 channels, s16, 705 kb/s
Archive files
For both the base game and expansion, archive files can be recognised by a table of contents (TOC) at the end of the .zbd file. This is a common strategy to be able to easily add entries to an archive without rewriting the entire archive. The new entry is written at the end, i.e. it overwrites the TOC, and then the TOC is written out fully with the new entry. This avoids having to rewrite the rest of the entries.
Known archive files are sound archives, reader archives, motion archives, mechlib archives, and save games. Other .zbd files may also contain multiple files, but are not archive-based (for example interpreter scripts, texture files).
Investigation (MW3)
The sound archives are good candidates to follow along, since their contents makes it obvious that the entry data is written from the start of the file (so the TOC must be at the end), and once extracted, you get .wav files that are easily validated to be correct (by listening to them).
For the base game, there are two fields at the end of the file:
#![allow(unused)] fn main() { struct Footer { version: u32, // always 1 count: u32, } }
The version of the TOC (u32, at -8), and number of entries in the TOC (u32, at -4). The version will always be 1.
Each entry in the TOC is 148 bytes long:
#![allow(unused)] fn main() { struct Entry { start: u32, length: u32, name: [u8; 64], // zero-terminated/padded garbage: [u8; 76], } }
The start of the TOC is found by calculating the length of the TOC (number of entries * 148), adding the TOC "footer" (count, version) to that, and subtracting it from the length of the file, or seeking from the end of the file. Then read the entries.
Each entry specifies the start of the entry's data in the file, the length of the entry's data in the file, the name of the entry (zero-terminated, and padded with null bytes), and a field I've called "garbage". This can largely be ignored. It was supposed to be flags, a comment and the file time:
#![allow(unused)] fn main() { struct Entry { start: u32, length: u32, name: [u8; 64], flags: u32, comment: [u8; 64], time: u64, } }
Where the time is actually a Windows FILETIME structure. Ignore the low and high parts in the documentation, the easiest way to read this is as a 64-bit value, which is then "the number of 100-nanosecond intervals that have elapsed since January 1, 1601, Coordinated Universal Time (UTC)." (i.e. the Windows epoch).
Unfortunately, in some files (like the mechlib), the entry data was not properly zeroed out, and so this contains random memory.
Another trap is that entries are not necessarily deduplicated. There can be two or more entries with the same name. In all the files I have, entries with the same name contain the same data, but this isn't a guarantee.
How the entry data is interpreted depends on the archive type.
Investigation (PM)
The Pirate's Moon archives are similar to the base game, but there are three fields and the end of the file, and they do not have a backwards-compatible layout:
#![allow(unused)] fn main() { struct Footer { version: u32, // always 2 count: u32, checksum: u32, } }
The version of the TOC (u32, at -12), the number of entries in the TOC (u32, at -8), and a checksum of the file data (u32, at -4). The version will always be 2. If they had left the version at -8, this would have made reading the file easier.
The new field is the checksum. For archive types other than reader archives, it will be 0. Maybe it was too time intensive to calculate the checksum for the bigger archives, or maybe they only introduced it to prevent cheating by modifiying the reader files, which are relatively easy to understand. It's unclear why it wasn't made backwards compatible though, or why the other archives didn't keep using version 1.
The checksum is an incorrectly implemented cyclic redundancy check (CRC32). It seems to be based on Ross William's A Painless Guide To CRC Error Detection Algorithms, specifically the "Roll Your Own Table-Driven Implementation" section. As noted in Michael Pohoreski (aka. Michaelangel007) excellent
CRC32 Demystified, for the code given the bits in each data byte aren't reversed. Of note is additionally the initialization value of 0x00000000, and the fact that the final value isn't inverted/xor'd with 0xFFFFFFFF, as some other implementations do. Based on this information, I have managed to write code for calculating the Pirate's Moon checksums using a pre-calculated table. The pre-calculated table used is a standard CRC32 with the polynomial 0x04C11DB7, roughly:
#![allow(unused)] fn main() { for index in 0..256u32 { let mut crc = index << 24; for _ in (1..9).rev() { if (crc & 0x80000000) == 0x80000000 { crc = (crc << 1) ^ 0x04C11DB7; } else { crc = crc << 1; } } CRC32_TABLE[index] = crc; } }
A running CRC32 can then easily be calculated for arbitrary input, starting with the initial value:
#![allow(unused)] fn main() { pub const CRC32_INIT: u32 = 0x00000000; fn crc32_update(crc: u32, buf: &[u8]) -> u32 { let mut crc = crc; for byte in buf { let index = (crc >> 24) ^ (*byte as u32); crc = CRC32_TABLE[index as usize] ^ (crc << 8); } crc } }
The CRC32 of an archive is calculated over all the entry data in the archive, in the order they are listed in the TOC, but does not include the TOC itself.
There is one more oddity for motion archives in PM. For these, the entry length will always be 1. The entry length can be calculated from the previous entry starting position, so e.g. sorting the entries by start, reversing them, and using the start of the TOC for the first (reversed)/last (unreversed) entry. Or, since the motion reading code can be made self-limiting, code can simply jump to the start and read the motion data.
Sound archives
Sound archives hold sound effects, used throughout the game in menus and in missions.
Investigation
Sound archives are the easiest type of archive to investigate in my opinion. Their contents makes it obvious how archive files are read.
The two hints as to what data these archives contain are that a) the 1.2 patch installs loose Waveform Audio Files, aka. WAVE or .wav into the zbd directory, and b) the starting data in the archives is b"RIFF \xe0\x02\x00WAVEfmt ", which is the magic RIFF header (Resource Interchange File Format), and a WAVE format.
There isn't much else to say about these files, since the hard part is reading the archive, and that code is common with other archives.
Maybe of interest for parsing the WAVE files to read the raw sound data as floating point values is that they are all mono or stereo files, and use only 8 or 16 bit samples. RIFF or WAVE parsing is out of scope for this documentation, but I have had no problems with parsing the sound files.
Another thing to remember is that as mentioned, the patch installs loose WAVE files in the zbd directory, which also need to be loaded to have all sound effects present.
In-game use
Sound effects are used throughout the game in menus and in missions. They are global, so it's easy to load them once and use them as needed throughout. With modern RAM sizes, this isn't a problem. The high fidelity sound archive is less than 100 MiB, and WAVE files are already uncompressed. Even if the sound data is parsed to floating point values, this should be less than 400 MiB.
Reader archives / binary reader files
Reader archives hold most of the games configuration in a Lisp-like list structure. Fair warning though that some of this information is duplicated inside anim.zbd files!
Binary and text reader files have the file extension .zrd, which could stand for Zipper Reader. Until 2022, I only knew of binary reader files. However, there exist text reader files, for example DefaultCtlConfig.zrd.
Investigation (MW3)
Once it is known how to read archive files (from e.g. the sound archives), the reader data is easy to figure out, since the binary structure is very simple and consistent.
To read a value, first a u32 (or i32) is read. This is the type of value, where 1 means integer (i32), 2 means float (f32), 3 means string, and 4 means list. No other types are seen. You can also think of the values as a tagged/discriminated union or a sum type.
For reading string values, read a u32 (or i32), which is the number of bytes in the string. Then read that many bytes. There is no zero-termination! One trap is that the string encoding is not exactly known. It could depend on the system's codepage. Interpreting the string as ASCII (0-127) seems to be the safest option, and the reader files never use values outside of ASCII. Another option would be to use codepage 1252 for the encoding.
For reading list values, simply read a u32 (or i32), which is the number of values in the list plus one (!). Then, read count - 1 items. Empty lists do exist, and list values can be of different types (so it is more like a tuple).
#![allow(unused)] fn main() { struct Integer { type_: u32, // always 1 value: i32, } struct Float { type_: u32, // always 2 value: f32, } struct String { type_: u32, // always 3 length: u32, value: [u8; length], // not zero-terminated/padded } struct List { type_: u32, // always 4 count: u32, values: [Integer/Float/String/List; count - 1], } }
The outermost value in a reader file seems to always be a list, so the data structure is self-terminating. This makes it easy to read the entire file.
While the binary structure is simple and consistent, the end result is not necessarily easy to consume. First, "keyed" data is annoying to look up for modern standards. There is no dictionary/map/object type. This means it's necessary to find the key in the list, and then the next index could be the data. There is no requirement a key is unique in a list. There is no requirement a key is followed by only one value. Sometimes, the following values are contained in a list (of size 1), sometimes, not:
[
"key1",
["value1"],
"key2",
0.5,
"key3",
0.3,
0.4,
]
Some lists are clearly a certain data type in the engine, but might contain different numbers of items, e.g. just a node name ["target_node"], a node name and translation ["target_node", 0.0, 0.0, 0.0], and potentially more forms.
So it seems like data lookup/interpretation is completely custom. Still, with a bit of care, it's possible to infer this and write code that uses the data.
Investigation (PM)
In Pirate's Moon, reader archives gained a checksum. They are the only archive type this is used for. Presumably, this was to make game modification harder, maybe to curb cheating online? Otherwise, they haven't changed.
In-game use
Reader files configure most of the game. However, animation definition archives (anim.zbd) contain the same animation definitions as the reader files, but compiled into better-defined C structures. So modifying an animation definition in a reader file may not change the game's behaviour. It's likely this was done because there are many animation definitions, and parsing them from the relatively unstructured reader files would make load times very long.
Converting reader files to animation definition archives faces the same problem as interpreting the reader data (custom code required). It's likely the development team had a tool to do this, or maybe the engine could dump animation definition archives from the loaded reader data (since the anim.zbd files look a lot like memory dumps with e.g. pointer values serialised).
Motion archives
Motion archives hold 'mech motion animation data, so how a 'mech model moves when it e.g. walks. However, the association of motion data with a 'mech model is determined by a reader file. Some 'mechs share motions/animations, and some motions are seemingly unused.
Investigation (MW3)
Motion archives are archive files. Each motion file is named <mech>_<motion>, so for example "bushwhacker_jump". Motion files begin with a header:
#![allow(unused)] fn main() { struct Header { version: u32, // always 4 loop_time: f32, // > 0.0 frame_count: u32, part_count: u32, unk16: f32, // always -1.0 unk20: f32, // always 1.0 } }
The version field will always be four (4). The loop time is a non-negative floating point value that describes how long the motion plays for. The frame count is the number of frames in the motion, which is inclusive. This means there are actually frame count + 1 frames of data to read. The last frame is always the same as the first frame. Apparently, this is a common technique to make looping animations easier. The part count is the number of parts of the model that will be animated. The last two fields are unknown, but are always set to negative one (-1.0) and positive one (1.0). Maybe they describe the coordinate system?
Next count parts are read:
#![allow(unused)] fn main() { struct Part { name_length: u32, name: [u8; name_length], // not zero-terminated flags: PartFlags, // always Translation + Rotation translations: [Vector3; frame_count + 1], rotations: [Quaternion; frame_count + 1], } bitflags PartFlags: u32 { Scale = 1 << 1, // 0x02 Rotation = 1 << 2, // 0x04 Translation = 1 << 3, // 0x08 } struct Vector3 { x: f32, y: f32, z: f32, } struct Quaternion { w: f32, x: f32, y: f32, z: f32, } }
Each part begins with a variable-length string (ASCII). There is no zero-termination. This is the part of the 'mech model that the motion affects. The flags field always specify translation (8) and rotation (4), and never scale (2) for obvious reasons (scaling any part would look weird on 'mechs). So it will always be twelve (12).
Then, the translations are read sequentially, and then the rotations are read sequentially. Again, there is one more frame to read than frame count indicates, and the first and last values will be the same. I believe the quaternion order is wxyz, since the quaternions work fine in Blender, but not in Unity, which uses xyzw order.
Investigation (PM)
Motion archive data doesn't change significantly in the expansion, but the archive does. Motion archives do not use checksumming; the checksum is always set to zero (0). Additionally, for some bizarre reason, the length of the data in the archive's TOC is always set to one (1). This can be highly inconvenient depending on the way archive entries are being read. A workaround is described in archive files.
In-game use
Motions are used to animate 'mech models during missions. Which motion is used for which 'mech model is specified in the reader files (dfn_<mech>.zrd in zbd/reader.zbd). Some 'mechs share motions, and some motions are unused.
Interpreter scripts
The interpreter scripts drive how the game engine loads the game data/worlds. They are all contained in a single file, interp.zbd.
Investigation
This is a quite short file, which is good. It is not an archive file.
#![allow(unused)] fn main() { struct Header { signature: u32, // always 0x08971119 version: u32, // always 7 count: u32, } }
The file starts with a signature (u32, magic number 0x08971119), a version (u32, always 7), and the number of scripts/count (u32). A table of contents (TOC) with script entries follows, which is easy to read since the count is known:
#![allow(unused)] fn main() { struct Entry { path: [u8; 120], // zero-terminated/padded last_modified: u32, offset: u32, } type Entries = [Entry; count]; }
The entry path seems to be an 120 byte string, ASCII, which is zero-terminated and padded with zeros/nulls. This can contain backslashes. They have the file extensions .gw and .gs, which one could guess to be game world and game script, respectively.
I have had success interpreting the last modified value as a timestamp, which gives datetimes around 1999 (for the v1.2 version). However, they may be some local timezone, and not UTC.
Finally, the offset is simply where the interpreter script data starts in the file. The the script data is written in the same order as the entries in the TOC, with no padding, so for reading all the data (instead of jumping to a script), it isn't strictly necessary. The script data must also be self-terminating, since the length isn't recorded in the TOC.
And indeed, immediately after the TOC the script data follows. Each script contains several lines. First, the size/length of the line (u32) is read. If it is zero (0), then the script is complete. Next, the token count of the line is read (u32). This indicates how many tokens the line contains.
The line is exactly size bytes. It contains exactly token count zero/null bytes (\0). These deliniate the arguments, so for two arguments, there are three tokens in a line: CommandName\0Argument1\0Argument2\0. The line should always end with a null byte (zero-terminated). There is no extra padding.
Null bytes or characters where probably chosen because they make splitting/tokenising the line trivial in C. However, since the command name and arguments don't contain spaces, it seems to be safe to convert the null bytes to spaces (if this is more convenient), and strip the final null byte.
#![allow(unused)] fn main() { struct Line { length: u32, token_count: u32, line: [u8; length], } }
Decoding the line as ASCII is safe, as is any ASCII-compatilbe encoding such as codepage 1251 or UTF-8. Encoding should probably be limited to ASCII though.
In-game use
Although the workings of the interpreter are obviously game engine internals, the commands are all human readable and self-describing. Presumably, the interpreter is driven by these scripts, and so they affect how most of the data is loaded. This can be seen from e.g. c1.gs:
ifdef USEZBD
GameZReadZBDFile %GAMEZ%
endif
ifndef USEZBD
... world setup code
endif
This looks like the interpreter scripts enabled prototyping of worlds before the assets were packed into a gamez.zbd file, probably for faster game development iteration. It also gives a bit of insight in how the game data is structured. There are several references to nodes, which indicates world data is maybe represented as a tree-like structure.
A comprehensive study of the filepaths in the interpreter scripts could maybe reveal how the game engine loaded unpacked/loose asset files, and make modding the existing engine easier.
String DLLs /translations
This file is known as:
messages.dllin RecoilMech3Msg.dllin MechWarrior 3 and Pirate's MoonStrings.dllin Crimson Skies (this one is different)
These files contain localised strings that are used by the game engine. Some of these strings are referred to by message keys (MSG_) in e.g. reader files.
Investigation (MW3)
Mech3Msg.dll has a single export:
$ rabin2 -E Mech3Msg.dll
[Exports]
nth paddr vaddr bind type size lib name
――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
1 0x00000b20 0x10001720 GLOBAL FUNC 0 Mech3Msg.dll ZLocGetID
This is somewhat unusual for a DLL that is ~120 KB in size. It also doesn't use many functions:
$ rabin2 -s Mech3Msg.dll
[Symbols]
nth paddr vaddr bind type size lib name
――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
1 0x00000b20 0x10001720 GLOBAL FUNC 0 Mech3Msg.dll ZLocGetID
1 0x00001000 0x10002000 NONE FUNC 0 MSVCRT.dll imp._initterm
2 0x00001004 0x10002004 NONE FUNC 0 MSVCRT.dll imp.malloc
3 0x00001008 0x10002008 NONE FUNC 0 MSVCRT.dll imp._adjust_fdiv
4 0x0000100c 0x1000200c NONE FUNC 0 MSVCRT.dll imp.free
And only links to msvcrt.dll (rabin2 -l Mech3Msg.dll), which is Microsoft's Visual C Runtime (MSVCRT). This hints that the DLL does not contain much functionality code-wise.
Printing the sections (rabin2 -S Mech3Msg.dll) shows the .rsrc section is the biggest, followed by .data. Printing the strings (rabin2 -z Mech3Msg.dll) shows that there are a lot of strings in both of these sections. Printing the resources shows that it contains a message table:
$ rabin2 -U Mech3Msg.dll
Resource 0
name: 1
timestamp: Thu Jan 1 00:00:00 1970
vaddr: 0x1000e060
size: 64.9K
type: MESSAGETABLE
language: LANG_ENGLISH
The German version predictably has the language LANG_GERMAN. This isn't an uncommon way of handling localisation, and is known as a resource-only DLL. Microsoft describes a similar approach to "localizing message strings". What is uncommon is the export, since resource-only DLLs usually contain no code.
The message table accounts for the strings in .rsrc, but not in .data.
However, the strings in the .data section all begin with the same prefix: MSG_. This also provides some indication of what the ZLocGetID function does. After simply trying some different arguments, it becomes apparent that when ZLocGetID is passed one of those message keys, it returns an unsigned 32-bit integer which corresponds to the entry ID in the table. So ZLocGetID and the .data section map human-readable strings to message table entry IDs. In Python - but only using a 32-bit version of Python and on Windows - this can be done as follows:
import ctypes
import ctypes.wintypes
lib = ctypes.CDLL("Mech3Msg.dll")
ZLocGetID = lib.ZLocGetID
ZLocGetID.argtypes = [ctypes.c_char_p]
ZLocGetID.restype = ctypes.c_int32
message_id = ZLocGetID(message_name)
Of course, enumerating the message keys via ZLocGetID is also not easy; a brute-force approach could take a long time. So message keys still need to be extracted from the .data section (see below).
The internal workings of Mech3Msg.dll are otherwise not interesting to this project. I think the DLL probably uses binary search to be able to quickly look up the entry IDs by message keys (at least, that's how I would've done it in 1999 and with C). Binary search requires the message keys to be sorted, which could be done at compile time, or run time. For a replacement Mech3Msg.dll, with a modern language, a hash-table/dictionary lookup would be more than sufficient. Or using C on a modern processor, a linear search would be fast enough.
Bonus facts:
- Not all messages are looked up by the message key! See below in "in-game use".
- Not all messages have corresponding values in the message table - it was probably easier to leave them in, knowing they're unused in the engine than recreate this data.
- Some messages are zeroed out by the patch, for example
MSG_GAME_NAME_DEBUG_VER. Rather interesting.
Investigation (CS)
Initially, it seems like Strings.dll is very similar to Mech3Msg.dll:
$ rabin2 -E Strings.dll
[Exports]
nth paddr vaddr bind type size lib name
―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
1 0x00001010 0x10001010 GLOBAL FUNC 0 Strings.dll ZLocGetStringID
Note the entry point is ZLocGetStringID, and not ZLocGetID. It also links to KERNEL32.dll instead of MSVCRT.dll, and references many more functions. The .data and .rsrc sections are still the biggest.
The most notable change is the type of resources:
$ rabin2 -U Strings.dll
Resource 0
name: 7
timestamp: Tue Jan 1 00:00:00 1980
vaddr: 0x100135b8
size: 636
type: STRING
language: LANG_ENGLISH
<truncated>
Resource 111
name: 1072
timestamp: Tue Jan 1 00:00:00 1980
vaddr: 0x1001d1d4
size: 238
type: STRING
language: LANG_ENGLISH
Resource 112
name: 1
timestamp: Tue Jan 1 00:00:00 1980
vaddr: 0x1001d2c4
size: 944
type: VERSION
language: LANG_ENGLISH
Resource 113
name: 1
timestamp: Tue Jan 1 00:00:00 1980
vaddr: 0x1001d674
size: 4
type: UNKNOWN (255)
language: LANG_ENGLISH
This means instead of using a message table, it uses a string table to store the message texts. In practise, this is a small change, but does require the resource section to be parsed differently.
As seen above, the DLL also includes a VERSION and UNKNOWN resource. It is not necessary to parse these to recover the messages.
In-game use
Some messages are looked up directly by entry ID. I found this out when I didn't preserve the entry IDs in a replacement DLL, and the "insert CD" message was incorrect. Even though new messages are added and old messages are removed in the new versions/patches, they preserve entry ID numbering between versions. A replacement DLL should also do this. A re-implementation doesn't have to.
Presumably, most messages are looked up by message key by the engine. Some reader files also reference message keys, which are presumably dynamically looked up when interpreting reader files.
Reading the message table
Luckily, Windows resources are somewhat well documented, either by Microsoft or third-parties. There are two options. On Windows, it is possible to use Windows APIs to read these resources, via LoadLibraryEx, and then FindResource/LoadResource, or FormatMessage specifically for message tables. The problem with the former functions are they less helpful for message tables, as the raw message table still needs to be parsed. The problem with the latter function is that it requires a message ID to load a specific message. Alternatively, it's trivial to read the entire message table on any platform/operating system.
There exist many libraries for parsing Portable Executables (PE), which is the "file format for executables, object code, DLLs and others used in 32-bit and 64-bit versions of Windows operating systems". They can often parse resource definitions also. So getting the raw message table data should be easy, especially since there is only one resource in the DLL. If a library doesn't support this, then the best approach is to parse the .rsrc section and look for RT_MESSAGETABLE = 11 (0x000B), and the appropriate locale ID en_US = 1033 (0x0409).
The format of the message table is described by MESSAGE_RESOURCE_DATA, MESSAGE_RESOURCE_BLOCK, and MESSAGE_RESOURCE_ENTRY, although they are pseudo-structures. Note that since MechWarrior 3 is a 32-bit application (as discussed in the introduction), the alignment for data is 32-bit or 4 bytes.
First, the number of blocks is read (u32). Next, the blocks are read, which are the low ID (u32), high ID (u32), and the offset to entries (u32):
#![allow(unused)] fn main() { struct Block { low_id: u32, high_id: u32, offset_to_entries: u32, } struct Data { count: u32, blocks: [Blocks; count], } }
Finally, the entries are read by iterating over the blocks, the most complicated step (but still easy).
For each block, it's offset from the start of the message table data is given. Blocks should be sequential, so it should be possible to simply iterate through the data, but I would recommend seeking to the position anyway. Since the entries are grouped into blocks, the entries from low ID (inclusive) to high ID (inclusive!) are read per block. The inclusive high ID can be a bit of a trap. It's very easy to not read the highest ID in a block by being off-by-one. For a block with only one message, the low ID and high ID are the same. For a block with two messages, the low ID could be e.g. 1 and the high ID would be e.g. 2. So in Python, the entry ID would be: for entry_id in range(low_id, high_id + 1).
#![allow(unused)] fn main() { struct Entry { length: u16, flags: u16, message: [u8; length - 4], // zero-terminated/padded } }
For each entry, the length is read first (u16), which is the length of the entire entry. Then the Unicode flags are read (u16). Expect this to be 0, since the messages are not Unicode (which in Microsoft-land means UTF-16 LE). Instead, the messages are encoded using the codepage appropriate for the language of the message table (aka. locale ID). Luckily for extraction, the English, German, and French locale IDs map to the same codepage (1251). This means that the messages simply need to be read with the codepage encoding, and they will decode properly (I have tested this on the German strings). So it is simply a matter of reading length - 4 bytes (remember, the length includes itself and the flags field) to get the message data, which is not quite the same as the message.
Messages are padded to be 32-bit aligned with null bytes (\0). Even though the length is known, messages have at least one null byte at the end (zero-terminated), presumably for C interoperability. Since codepage 1251 shares the first 128 characters with ASCII, these can be safely stripped before decoding the string (i.e. in byte form), or afterwards.
Additionally, even single line messages are terminated with the DOS/Windows line ending \r\n (this isn't always the case, but common and true in this case). As long as they are at the end of the message, you may wish to also strip these for convenience. Messages can also contain DOS/Windows newlines within the message, which should be preserved.
It's also worth pointing out that some of the messages contain formatting placeholders, that are specific to those messages. There is no way of knowing what values were intended, other than looking for the format placeholders (e.g. %1, %2) and inferring this
from the context of the message (or reverse-engineering the engine, which this project does not encourage).
Reading the string table
This is very analogue to message tables. It is possible to use Windows APIs, or to parse the resources using a PE library/by hand.
Raymond Chen has a post about "The format of string resources" on his blog "The Old New Thing". Roughly speaking, string tables are split by the resource compiler into blocks of 16 contiguous IDs. This is why the DLL contains 112 STRING resources (RT_STRING = 6). The resource name gives the block ID.
Notice how similar this is to a message table, except that while the message table is a single resource that contains blocks, the string table effectively makes the blocks available to be loaded separately, without parsing the entire string table. That is the resource data entries give the data offset/size of a single block of strings. One extra complication is that a single block could have multiple resource data entries for each language, but this doesn't happen.
From the block ID, the string IDs can be derived:
#![allow(unused)] fn main() { let block_min = (block_id - 1) * 16; let block_max = block_id * 16; }
I'm sure there's a Unicode flag somewhere in the resource information; for Crimson Skies the messages are always "Unicode". This is Microsoft-speak for UTF-16 little-endian, and a whole other can of worms. I digress. The strings are not zero-terminated. Instead, first a u16 value is read, which is the "length" of the string. To be pedantic, it is not the length, but the number of WCHAR/u16 values which comprise the string. If you want to know more, see "surrogate pairs", Unicode codepoints, and the meta-question of what the length of string should be (bytes, codepoints, grapheme clusters, etc).
Because the blocks are contiguous, missing entries are zero-length strings, so a zero length should be interpreted as missing.
In any case, for a given length > 0:
#![allow(unused)] fn main() { // u16 values must be read as little endian on all systems! let wchars = [u16; length]; // or using bytes, but note these also must be byte-swapped on big endian systems! let bytes = [u8; length * 2]; }
Reading the message keys
Presumably, you'll be using a PE parsing library. Start from the .data section. The first bytes are not important to understand. They are part of the common runtime (CRT) initialisation, generally called .CRT$XCA/__xc_a, .CRT$XCU_, and .CRT$XCZ/__xc_z. For MechWarrior 3 or Pirate's Moon, simply skip or read these four (4) u32 values (16 bytes). They should all be zero. For Recoil or Crimson Skies, skip 48 bytes. They are not all zero.
The data that follows are clearly constants defined in the original code. There is a sort of entry table for the message keys, that consists of the absolute memory offset of the message key string (u32), and the corresponding message table entry ID (u32). There is no easy way of knowing when the table has fully been read. I suggest checking if the offset is in the bounds of the .data section, since the string data produces values outside this range when accidentally interpreted as an integer.
Given the memory offset of the start of the .data section, the relative offset of the message key is easy to determine by subtracting the start offset from the absolute offset read previously. Seek to that position, and read the message key until encountering a null byte (\0). All message keys will be ASCII.
For manual verification, it's possible to use e.g. rabin2 to extract the strings, filter only the ones beginning with MSG_, and compare that to the result of parsing the .data section.
Texture packages
Texture packages hold textures or images, used throughout the game.
Investigation
I've had to awkwardly name the texture files "packages". They contain several textures/images, but are not archive-based. Most of them are for textures, but textures are simply images mapped to 3D surfaces. Since all textures are images, but not all images are textures, I'll call the data an image, not a texture.
RC, MW, PM, and CS texture packages are read in exactly the same way. The only difference is that in the base game, no package uses global palettes.
File structure
Packages start with a header:
#![allow(unused)] fn main() { struct Header { unk00: u32, // always 0 unk04: u32, // always 1 global_palette_count: i32, // or u32 image_count: u32, // or i32 unk16: u32, // always 0 unk20: u32, // always 0 } }
Only two fields in the header are useful. The global palette count (i32 or u32) indicates how many global palettes are used. The base game doesn't use them, so this will be zero (0). The expansion does for some packages. It's recommended to read this as an i32, as textures that don't use a global palette signify this with -1. The image count (u32 or i32) is self-explanatory, and should be at least one (1) or more. Next there is a table of contents, with image count entries:
#![allow(unused)] fn main() { struct Entry { name: [u8; 32], // zero-terminated/padded start_offset: u32, global_palette_index: i32, } }
The name of the image is a 32 byte string; assume ASCII encoding. It is zero-terminated and padded with zeros/nulls. The start offset (u32) is the offset of the image data in the package. This means the image data must be self-describing/self-terminating. The global palette index indicates if/which global palette is used. Images that don't use a global palette have this set to -1; otherwise the index is between 0 (inclusive) and global palette count (exclusive).
If there are any global palettes, they are read next. Global palettes are always 512 bytes long, or 256 * u16 packaged colour values in RGB565 format. How to interpret and unpack these values is described a bit later.
#![allow(unused)] fn main() { struct GlobalPalette { values: [u16; 256], } // alternatively struct GlobalPalette { values: [u8; 256 * 2], } }
Next, the image data is read in the same order as in the TOC. The data is read contiguously, so the start offset isn't needed. Or, it can be used for verification that the image data has been read completely, since the length of the image data isn't known from the TOC.
Each images starts with a header of information:
#![allow(unused)] fn main() { struct ImageInfo { flags: ImageFlags, width: u16, height: u16, unk08: u32, // always 0 palette_count: u16, stretch: ImageStretch, } enum ImageStretch: u16 { None = 0, Vertical = 1, Horizontal = 2, Both = 3, /// Crimson Skies only Unk4 = 4, /// Crimson Skies only Unk7 = 7, /// Crimson Skies only Unk8 = 8, } bitflags ImageFlags: u32 { ColorDepth = 1 << 0, // 0x01 HasAlpha = 1 << 1, // 0x02 NoAlpha = 1 << 2, // 0x04 FullAlpha = 1 << 3, // 0x08 GlobalPalette = 1 << 4, // 0x10 ImageLoaded = 1 << 5, // 0x20 AlphaLoaded = 1 << 6, // 0x40 PaletteLoaded = 1 << 7, // 0x80 } }
First, the flags. The first flag, which is assumed to be related to colour depth, is always set and isn't further important - the colour depth is always 16 bit/2 bytes per pixel.
Next are the alpha channel flags, which are a mess. If "no alpha" is set, then "has alpha" and "full alpha" must not be set. This indicates the image has no alpha channel. If "no alpha" is unset, then "has alpha" must be set. This indicates the image has an alpha channel. If "full alpha" is set, then the alpha channel data is 8 bits/1 byte per pixel; otherwise, the alpha channel/transparency is derived from the colour information and there is no alpha channel data. The exact way the alpha channel is loaded is discussed with the image data.
The global palette flag is set if and only if the entry in the TOC specified a global palette index.
Finally, the last three flags are assumed to be some indication of what data the game engine has loaded. They can be safely ignored for interpreting the image data, but do occur in the files.
The width (u16) and height (u16) are obvious. The next value (u32) is unknown, but always zero (0). The palette count (u16) specifies how many colour values the palette contains. Images that aren't palette-based have this set to zero (0). Importantly, this applies to both global and local palettes. So even though global palettes have enough data for 256 colour values, fewer colours may be used when interpreting image data.
Lastly, the stretch field indicates if an image should be stretched after it has been decoded/before it is displayed. This seems to be used for e.g. environment textures that require more vertical resolution than horizontal resolution, possibly to save space but still have the image be square (I think square textures used to provide a performance benefit for some graphics cards/operations).
Image data
Colour image pixel data (not palette-based)
Colour images are images with a zero palette count. The colour data is read first. It is a bitmap with two (2) bytes per pixel of size width * height (so width * height * 2 bytes in total).
#![allow(unused)] fn main() { struct ColorData { values: [u16; width * height], } // alternatively struct ColorData { values: [u8; width * height * 2], } }
Each pixel is 2 bytes/16 bits, and is a packed RGB format known as 565. This was determined by trying out different packed RGB formats and seeing if the colours look correct. The RGB565 format means red has 5 bits, green has 6 bits, and blue has 5 bits of information. This is the layout in memory, where each cell is a byte/u8:
|GGGBBBBB|RRRRRGGG|
|7 0|7 0|
If read as one little-endian u16 (the default on x86), this is the layout:
|BBBBBGGG GGGRRRRR|
|^ ^ ^ ^|
|0 5 7 8 11 15|
While it is important to know the bit patterns, there's a temptation to extract the individual colour values. But in my experience, this isn't a good approach. Let's take a minute to think about how to map an RGB565 encoded pixel to the standard RGB888 encoding (where each colour value occupies 1 byte). Simply shifting a 5 or 6 bit value doesn't produce full brightness:
#![allow(unused)] fn main() { let value = (0b11111 << 3); value == 0b11111000; // => true value < 0b11111111; // => true }
So simple shifting produces a darker than usual image. Instead, the values have to be interpolated. I don't know enough about computer graphics to say if it is important to apply gamma correction when mapping from RGB565 to RGB888, so I've assumed the assets are stored in linear RGB and therefore linear interpolation is correct.
5 bit values range from 0 to 31 (inclusive), 6 bit values range from 0 to 63 (inclusive), and 8 bit values range from 0 to 255 (inclusive). This means that the values can be mapped to a floating point value in the range of 0.0 to 1.0 (inclusive) by dividing by the maximum (either 31 or 63), and then the floating point value can be mapped to the 8 bit range by multiplying by the maximum (255). For floating point accuracy reasons, I believe it's best to multiply first, and then divide. The result should be the same.
Finally, the floating point value must be converted to an integer. Rounding should be considered, as often, converting to an integer often simply truncates the fractional/decimal part. But rounding is also complicated, and there are several strategies like banker's rounding/rounding half to even. Given the input is limited in precision, I've simply chosen to round up, with a nice trick that adding 0.5 to a (positive) floating point value before truncating rounds up.
With this, it's easy to build a lookup table to map any RGB565 colour value to an RGB888 values, which is much faster than doing this conversion for each pixel. A Rust implementation could look like this:
#![allow(unused)] fn main() { let rgb888: Vec<u32> = (u16::MIN..=u16::MAX) .map(|rgb565| { let red_bits = (rgb565 >> 11) & 0b11111; assert!(red_bits <= 31, "r5 {:#b}", red_bits); let red_lerp = ((red_bits as f64) * 255.0 / 31.0 + 0.5) as u32; assert!(red_lerp < 256, "r8 {:#b}", red_lerp); let green_bits = (rgb565 >> 5) & 0b111111; assert!(green_bits <= 63, "g6 {:#b}", green_bits); let green_lerp = ((green_bits as f64) * 255.0 / 63.0 + 0.5) as u32; assert!(green_lerp < 256, "g8 {:#b}", green_lerp); let blue_bits = (rgb565>> 0) & 0b11111; assert!(blue_bits <= 31, "b5 {:#b}", blue_bits); let blue_lerp = ((blue_bits as f64) * 255.0 / 31.0 + 0.5) as u32; assert!(blue_lerp < 256, "b8 {:#b}", blue_lerp); (red_lerp << 16) | (green_lerp << 8) | (blue_lerp << 0) }) .collect(); // black assert_eq!(rgb888[0b0000000000000000], 0x000000); // white assert_eq!(rgb888[0b1111111111111111], 0xFFFFFF); // red assert_eq!(rgb888[0b1111100000000000], 0xFF0000); // green assert_eq!(rgb888[0b0000011111100000], 0x00FF00); // blue assert_eq!(rgb888[0b0000000000011111], 0x0000FF); // red + green assert_eq!(rgb888[0b0000011111111111], 0x00FFFF); // red + blue assert_eq!(rgb888[0b1111100000011111], 0xFF00FF); // green + blue assert_eq!(rgb888[0b1111111111100000], 0xFFFF00); }
The same approach can be used for decoding colour image data and palette colour data.
Colour image simple alpha
The alpha channel for a colour image with simple alpha (so not full alpha) is derived from the colour data. A completely black pixel (0x0000) is 0% opaque/100% transparent (usually 0), any other colour is 100% opaque/0% transparent (usually 255).
Colour image full alpha data
For an image with full alpha, the alpha channel data is read after the image data. It is a bitmap with one (1) byte per pixel of size width * height (so width * height bytes in total).
#![allow(unused)] fn main() { struct FullAlphaData { values: [u8; width * height], } }
The values range from 0, which is 0% opaque/100% transparent, to 255, which is 100% opaque/0% transparent.
Palette-based image pixel data
Palette-based images are images with a greater-than zero palette count. This means the image data is an array of palette indices, that are then mapped to colours via the palette. Palette-based images can either use a predefined global palette, or a palette specific to the image (local palette).
The palette index data is read first. It is a bitmap with one (1) byte per pixel of size width * height (so width * height bytes in total).
#![allow(unused)] fn main() { struct PaletteIndexData { values: [u8; width * height], } }
I'll shortly discuss how to map this palette index data to colour data.
Palette-based image simple alpha
It currently isn't known how to derive a simple alpha channel for palette-based images. This is due to a lack of interest. Since the palette-based images are more limited in colour due to palette quantisation (a maximum of 256 distinct colours), there is little reason to use them on modern PCs. Consequently, it hasn't been investigated. A common strategy for simple transparency in other palette-based image formats is to designate one index as transparent (e.g. likely the first, possibly the last, but some allow any index to be the transparent one).
Palette-based image full alpha data
This is exactly like the colour image. It is a bitmap with one (1) byte per pixel of size width * height (so width * height bytes in total).
Palette-based image palette colour data
If the image isn't using a global palette, the palette colour data is read after the palette index data and full alpha data (if any).
#![allow(unused)] fn main() { struct LocalPalette { values: [u16; palette_count], } // alternatively struct LocalPalette { values: [u8; palette_count * 2], } }
Just like colour image data and global palette data, these are RGB565 format colour values.
If the image is using a global palette, then that must be restricted to the number of colour values indicated by palette count.
Using palette-based image data
There are several options here. Some image formats support palette-based images. However, few support palette-based colour channels and a full alpha channel. For preservation, the best strategy might be to output the image data as a palette PNG and the alpha data as a grey scale PNG. Alternatively, it's obviously possible to map each pixel to RGB888 via the palette, and optionally store the palette separately.
Recap
- All images have an image header
- For colour images:
- Read the image data
- Read the full alpha channel (if the image has one)
- For palette-based images:
- Read the palette index data
- Read the full alpha channel (if the image has one)
- Read the local palette colour data (if not using a global palette)
In-game use
Textures and images are used basically everywhere.
Mechlib archives
Mechlib archives hold detailed and low-resolution 'mech models, 'mech cockpit models, and mechlib model data.
Investigation (MW3)
Mechlib archives are archive files. They contain three unique files, format, version, materials. Otherwise, all files are models with the ending .flt.
Format and version
Both of these files are four (4) bytes long, and can be read as either a u32 or i32. The format value is always one (1). The version value is 27 for the base game.
Materials
The materials file is very similar to but slightly different than materials information in GameZ files.
The difference in the Mechlib is that the texture_ident field is a pointer, not the index. In the GameZ file, since the texture names are written first, the field holds the texture index, which is then replaced with a pointer to the texture. In the mechlib archive, this is the raw pointer value, since the texture name is written after the structure (discussed shortly).
So, in the material file, the number of materials in the file (count, u32 or i32) comes first. Next, count materials are read. Additionally, if the material is textured, a variable string that is the texture name follows the material structure immediately:
#![allow(unused)] fn main() { struct MaterialName { length: u32, name: [u8; length], // not zero-terminated } }
Assume this is ASCII. There is no zero-termination, so if this is required, allocate length + 1 bytes.
Textured materials
Textured materials are the same as GameZ, with the following exceptions:
- Mechlib materials cannot be cycled, so the
Cycledflag (0x04) is never set, and the cycle pointer field is always zero (0)/null. - As described, the
texture_identfield is not an index, but a pointer. The pointer value is - as always - garbage from when the memory was dumped. - The terrain/soil type is always
Default(0).
Coloured materials
Untextured or coloured materials are the same as GameZ.
Model files
Like the materials file, model files are very similar to but slightly different than models in gamez.zbd files. Model files are also quite complex.
First, some background. MechWarrior 3 uses so-called "nodes" to represent information in the engine. There are hints to this in the reader files and interpreter scripts. In mechlib.zbd, the only allowed node type is a 3D object node. GameZ files can contain other nodes.
I describe all nodes separately, since the structures are rather large. As a quick refresher, all nodes share a base structure, and then have node type specific data.
I also describe mesh data structures in GameZ, since they are largely the same.
Investigation (PM)
The expansion files are similar to the base game, however many data structures around the nodes have changed.
Format and version
Both of these files are four (4) bytes long, and can be read as either a u32 or i32. The format value is always one (1). The version value is 41 for the expansion.
Materials
Materials are read exactly the same as the base game.
Model files
Model files are ready the same way as the base game, but many data structures are different. Note that while in the base game, only 3D object nodes are allowed, in the expansion both 3D object nodes and LOD (level of detail) nodes are present.
I describe all nodes separately, since the structures are rather large and shared with GameZ files.
I also describe mesh data structures in GameZ, since they are largely the same.
In-game use
These models are used in-game and in the mechlab screen.
GameZ files
GameZ files hold the game's world assets (except for 'mech models).
Investigation (MW3)
GameZ files begin with a header, which is a mish-mash of information:
#![allow(unused)] fn main() { struct HeaderMw { signature: u32, // always 0x02971222 version: u32, // always 27 texture_count: u32, textures_offset: u32, materials_offset: u32, meshes_offset: u32, node_array_size: u32, node_count: u32, nodes_offset: u32, } }
The signature (u32) is the magic number 0x02971222. The version (u32) is always 27, which matches the mechlib archives version.
The other values are used for accessing the four big blocks of information: textures, materials, meshes, and nodes. This is also not so different from the mechlib archives, although there are significant differences in the way the data is read/written. It isn't known why this is. The offsets aren't strictly necessary for parsing, since the data is written without padding, and so can be used for verifying the different parsing stages were successful/parsed all the information.
Textures
Reading the texture infos uses the texture count from the header. Expect this to be less than 4096 textures for sanity checking (if desired). There is no header, instead simply read texture count texture information structures:
#![allow(unused)] fn main() { struct TextureInfo { unk00: u32, // always 0 unk04: u32, // always 0 texture: [u8; 20], // suffixed usage: TextureUsage, // always Used (2) index: u32, // always 0 unk36: i32, // always -1 } enum TextureUsage: u32 { Unused = 0, Unknown1 = 1, Used = 2, Unknown3 = 3, } type TextureInfos = [TextureInfo; texture_count]; }
As with many structures, this seems to be a memory dump of an in-engine structure. So most of these fields are unimportant for simply reading the game data.
The only important field is the texture name, which is interesting to parse. Assume ASCII encoding. Firstly, it is shorter than most other fixed-length strings in game data (20 bytes, instead of the usual 32 bytes).
Secondly, it is suffixed. Basically, the name will be texture\0tif\0\0, that is the name of the texture/image as it appears in the texture packages, followed by a null byte, followed by the suffix/file extension tif (usually), finally padded with more null bytes until the length of 20 bytes. So it seems like the assets were Tag Image File Format (TIFF) images, and then the GameZ generation code didn't strip the file extension, but simply overwrote the period of the file extension with a null byte.
For code that only wants to read the texture name, this doesn't matter. Simply read until the first null byte and discard the rest. For code that wishes to e.g. round-trip this information in a binary-accurate way, it's more complicated. In every case, there will be an initial null byte. The suffix and further padding may be cut off by the 20 byte limit. Any padding after the suffix will also be only more null bytes. So restoring the period and therefore the file extension is a feasible approach.
Not much else is known about the other fields. unk00 (u32?) is always zero (0), and could've been a pointer. unk04 (u32?) is always zero (0). I'm told it could cause the engine to execute additional dynamic code on loading. The usage field (u32?) seems to allow tracking of if the texture is no longer in use by the engine and can be removed from memory. It will always be two (2) in the file, which corresponds to "Used". The index field (u32 or i32) tracks the texture's index in the global texture array. It will always be zero (0) in the file, since no index has been assigned until it is loaded. unk36 (i32) is always negative one (-1).
Materials
Materials header
The materials block does have a header:
#![allow(unused)] fn main() { struct MaterialHeader { array_size: i32, // always >= 0, <= 0xFFFF count: i32, // always >= 0, <= array_size index_max: i32, // always == count unk12: i32, // always -1 } }
The field unk12 is unknown, but is always negative one (-1).
The other fields are interdependent. The material array size indicates how big the material array for this world is expected to the in the worst case. This allows the engine to allocate more or less memory depending on the world. Expect this to be zero (0) or greater, and less than 65535/0xFFFF. Next is the actual count of materials in the file. Naturally, this must be zero (0) or greater, and less than the array size. Finally is the maximum index or next index, which is used to track which index to use for any further materials. This will always be the same as the material count, since they are loaded at once, producing contiguous indices. Shortly, we'll see that the material indices are i16 values. It's unclear why the values in the header are aligned to 32 bits/4 bytes. This is why I've indicated them to be read as i32, with additional bounds checking. Per C structure packing rules, you'd expected if they were i16 that the header would be smaller/more tightly packed.
Materials are read in three phases. The valid materials first, then zeroed-out materials, and then material cycle data.
Materials information
Next, count materials are read. Each material has a main structure, which is the same structure as the Mechlib materials, but is read and interpreted slightly different. Unlike the Mechlib materials, material indices are also read. First, the structures:
#![allow(unused)] fn main() { struct Material { alpha: u8, flags: MaterialFlags, rgb: u16, red: f32, green: f32, blue: f32, texture_ident: u32, unk20: f32, // always 0.0 unk24: f32, // always 0.5 unk28: f32, // always 0.5 soil: u32, cycle_ptr: u32, } bitflags MaterialFlags: u8 { Textured = 1 << 0, // 0x01 Unknown = 1 << 1, // 0x02 Cycled = 1 << 2, // 0x04 Always = 1 << 4, // 0x08 Never = 1 << 5, // 0x10 } struct MaterialIndices { index1: i16, index2: i16, } }
First, read the material information. Then read the material indices. Repeat until count materials have been read.
A lot isn't known about the material information. It seems to be dump of an in-game structure, as it contains what seem to be pointers. Some fields are always set to the same value. The unk20 field is always 0.0, the unk24 and unk28 fields are always 0.5.
The Always flag (0x08) is always set, the Never flag (0x10) is never set. The most important flag is the Textured flag. This indicates whether the material has a texture or not.
Terrain/soil type
The terrain/soil index indicates how polygons with that will be classified/behave in the engine.
In Recoil, the following types are hard-coded in the executable:
[
"default", # 0
"water", # 1
"seafloor", # 2
"quicksand", # 3
"lava", # 4
"fire", # 5
]
The range of values is 0..5, although 2/seafloor does not seem to be used.
These types are also hard-coded in MechWarrior 3, but the range of values is 0..13. In the soils.zrd file, the following types are defined:
[
"dirt", # 6
"mud", # 7
"grass", # 8
"concrete", # 9
"snow", # 10
"mech", # 11
"silt", # 12
"noslip", # 13
]
As indicated, these seem to be concatenated with the hard-coded list. The value 11/mech does not seem to be used in GameZ (or the Mechlib).
For Crimson Skies, soils.zrd is also different.
Textured materials
#![allow(unused)] fn main() { struct Material { alpha: u8, // always 0xFF/255 // always: 0x01/Textured // variable: 0x02/Unknown // variable: 0x04/Cycled // always: 0x08/Always (except for RC) // never: 0x10/Never flags: MaterialFlags, rgb: u16, // always 0x7FFF/32767 red: f32, // always 255.0 green: f32, // always 255.0 blue: f32, // always 255.0 texture_ident: u32, unk20: f32, // always 0.0 unk24: f32, // always 0.5 unk28: f32, // always 0.5 soil: u32, // 0..13 cycle_ptr: u32, } }
Textured materials always have alpha set to 255/0xFF, since textures can include their own alpha data. The rgb field set to 32767/0x7FFF, and the red, green, and blue fields set to 255.0 (which is white). The unknown flag may or may not be set.
Textured materials can have the cycled flag set, which indicates that the material has multiple textures that are cycled through, creating an animated effect. Note that Mechlib textured materials cannot be cycled. If this flag is set, the cycle pointer should be non-zero/non-null. If the flag is unset, the cycle pointer field is always zero (0)/null.
In the GameZ file, texture_ident field is an index to the texture info. This index must be less than the texture count.
Coloured materials
#![allow(unused)] fn main() { struct Material { alpha: u8, // never: 0x01/Textured // never: 0x02/Unknown // never: 0x04/Cycled // always: 0x08/Always (except for RC) // never: 0x10/Never flags: MaterialFlags, rgb: u16, // always 0x0000/0 red: f32, green: f32, blue: f32, texture_ident: u32, // always 0 unk20: f32, // always 0.0 unk24: f32, // always 0.5 unk28: f32, // always 0.5 soil: u32, // 0..13 cycle_ptr: u32, // always 0 } }
Untextured or coloured materials always have no flags set except for the "Always" flag (0x08).
The rgb field is always zero (0/0x0000). This deserved a bit of discussion. Textures use a packed colour value format known as RGB565, and textured materials have their colour set to white. For textured materials, rgb is set to 0x7FFF, which corresponds to white in the RGB555 format. So I have assumed this field was intended to be used as a packed colour, but for some reason wasn't used.
The red, green, and blue fields indicate the colour of the material, in an range of 0.0 .. 255.0.
The texture_ident field is always 0. Since the Cycled flag (0x04) is never set, the cycle pointer is always zero (0)/null.
Material indices
The expected indices can be calculated from the material index when reading. Say index is the value from 0 to count when reading the materials. The expected value for index1 and index2 are:
#![allow(unused)] fn main() { let mut expected_index1 = index + 1; if expected_index1 >= count { expected_index1 = -1; } let mut expected_index2 = index - 1; if expected_index2 < 0 { expected_index2 = -1; } }
So basically, index1 is the next index, and index2 is the previous. It seems like these are used for bookkeeping. Since they are so easy to calculate, discarding them is fine.
Zeroed-out materials
If there is a difference between the material count and the array size, then there will be array size - count zeroed-out material structures. This means all bytes/fields will be zero. You can basically loop from count to array size, and this is in fact advisable since the material indices will not be zeroed out. In fact, they will be the reverse of the filled in materials:
#![allow(unused)] fn main() { let mut expected_index1 = index - 1; if expected_index1 < count { expected_index1 = -1; } let mut expected_index2 = index + 1; if expected_index2 >= array_size { expected_index2 = -1; } }
This especially indicates these files are just dumps of in-engine data, if the (assumed) raw pointer values weren't enough evidence. It really does seem like this is just a dump of some internal array, since there is really no reason to write these zeroed-out structures (they contain no real information, so space could have been saved here).
Material cycle data
Finally, after the materials information, and zeroed-out materials, the material cycle data is read. This is basically in-order, so loop through all the previously read non-zeroed-out materials, and if they have the cycled flag set/cycled pointer non-null, read the cycle information:
#![allow(unused)] fn main() { struct CycleInfo { unk00: u32, // always 0 or 1 (boolean) unk04: u32, unk08: u32, // always 0 unk12: f32, // always >= 2.0 and <= 16.0 count1: u32, count2: u32, // always == count1 data_ptr; u32, // always != 0 } }
Not much is known about this structure, again it is probably used for keeping track of the material's cycle data. unk00 is always zero (0) or one (1), so a Boolean. unk04 is variable. unk08 is always zero (0). unk12 is a floating point value always greater or equal to 2.0, and less than or equal to 16.0. The two count values are always equal, and indicate the cycle length/number of textures in the cycle. Finally, the pointer is always non-zero, presumably this pointed to a block of memory that held the texture indices or pointers for the cycle, which are read next.
The important piece of information is the cycle count. Read this many u32 after the cycle information, which are the cycle's texture indices, basically:
#![allow(unused)] fn main() { struct CycleTextures { texture_index: [u32; count1], } }
Again, all of these values should be less than the total texture count. As far as I can see, the texture index (texture_ident) from the materials information isn't used for cycled textures, instead it's only these.
Meshes
From the main header, meshes_offset gives the offset to the meshes header, which looks like this:
#![allow(unused)] fn main() { struct MeshesHeader { array_size: i32, // always >= 0, <= 0xFFFF count: i32, // always >= 0, <= array_size index_max: i32, // always == count } }
This is very similar to the materials header. The fields are interdependent. The mesh array size indicates how big the mesh array for this world is expected to the in the worst case. Expect this to be zero (0) or greater, and less than 65535/0xFFFF. Next is the actual count of meshes in the file. Naturally, this must be zero (0) or greater, and less than the array size. Finally is the maximum index or next index, which is used to track which index to use for any further meshes. This will always be the same as the mesh count.
Meshes are read in three phases. The valid mesh headers or mesh information first, then zeroed-out mesh headers/information, and then mesh data.
Mesh information
The mesh information is a large structure of 92 bytes:
#![allow(unused)] fn main() { struct MeshInfoMw { unk00: u32, // always 0 or 1 (bool) unk04: u32, // always 0 or 1 unk08: u32, parent_count: u32, // 12, always > 0 polygon_count: u32, // 16 vertex_count: u32, // 20 normal_count: u32, // 24 morph_count: u32, // 28 light_count: u32, // 32 unk36: u32, // always 0 unk40: f32, unk44: f32, unk48: u32, // always 0 polygons_ptr: u32, // 52 vertices_ptr: u32, // 56 normals_ptr: u32, // 60 lights_ptr: u32, // 64 morphs_ptr: u32, // 68 unk72: f32, unk76: f32, unk80: f32, unk84: f32, unk88: u32, // always 0 } type MeshOffset = u32; // or i32 type MeshIndex = i32; type MeshInfosMW = [(MeshInfoMW, MeshOffset); count]; type ZeroInfosMW = [(MeshInfoMW, MeshIndex); (array_size - count)]; }
The most important piece of information is the polygon count. If this is zero (0), then the vertex count, normal count, and morph count will all be zero (0). Note that the counts can also be zero if the polygon count is non-zero. You might expect the light count to also be zero, and this would make sense, but is not true in at least one case.
Pointers will be zero/null if the corresponding count is zero (0), and will be non-zero/non-null if the corresponding count is positive.
The fields unk00 and unk04 will always be zero (0) or one (1). In Pirate's Moon, unk04 can also be two (2), so it's assumed this is not a boolean.
The parent count will always be greater than zero. The fields unk36, unk48, and unk88 will always be zero (0). The other fields are unknown.
The mechlib archive has a similar data structure, which does not include the final member. dataOffset indicates the absolute offset of the mesh data in the GameZ file. Since the mesh data is written in order, the mesh data offset must be greater than the last (or for the first, after all the mesh information and zeroed-out mesh information), and less than the next block (the nodes).
As an aside, internally this is probably used as the next mesh index, just like the materials did.
Zeroed-out mesh information
If there is a difference between the meshes count and the array size, then there will be array size - count zeroed-out mesh information structures. This means all bytes/fields will be zero. You can basically loop from count to array size, and this is in fact advisable since in this case, the mesh data offset is instead the mesh index. The mesh index wants to be loaded as an i32, not a u32 as might be more useful for the mesh data offset:
#![allow(unused)] fn main() { let mut expected_index: i32 = index + 1; if expected_index >= array_size { expected_index = -1; } }
Mesh data
Next, the mesh data is read for any filled in mesh information (not zeroed-out). The offset of the start of this data should match the previously read mesh data offset, but can be read sequentially without seeking.
Reading the mesh data is dynamic, based on the counts:
- Read vertex count vertices (where each is a vector of three f32)
- Read normal count normals (where each is a vector of three f32)
- Read morph count morphs(?) (where each is a vector of three f32)
- Read the lights
- Read the polygons
#![allow(unused)] fn main() { struct Vec3 { x: f32, y: f32, z: f32, } struct Vertices { vertices: [Vec3; vertex_count], } struct Normals { normals: [Vec3; normal_count], } struct Morphs { morphs: [Vec3; morph_count], } }
Light information and data
The light information is largely unexplored and read in two phases. First, light count light information structures are read, each of 76 bytes in size:
#![allow(unused)] fn main() { struct LightInfoMw { unk00: u32, unk04: u32, unk08: u32, extra_count: u32, unk16: u32, unk20: u32, unk24: u32, unk28: f32, unk32: f32, unk36: f32, unk40: f32, ptr: u32, unk48: f32, unk52: f32, unk56: f32, unk60: f32, unk64: f32, unk68: f32, unk72: f32, } // probably good to combine lights + extras // in real code struct Lights { lights: [LightInfo; light_count], // pseudo-code: extra_count is variable! extras: [[Vec3; extra_count]; light_count], } }
The important field here is at offset 12, which is a u32 or i32 and indicates how much extra data to read. This data is read after all the light information. In this case, loop over the light information, and read extra count vertices (where each is a vector of the f32).
More research is needed on what the lights do.
Polygon information and data
The polygon information structure is 36 bytes:
#![allow(unused)] fn main() { struct PolygonInfoMw { vertex_info: u32, // always <= 0x3FF unk04: u32, // always >= 0, <= 20 vertices_ptr: u32, // always != 0 normals_ptr: u32, uvs_ptr: u32, colors_ptr: u32, // always != 0 unk_ptr: u32, // always != 0 material_index: u32, material_info: u32, } type PolygonInfosMw = [PolygonInfoMw; polygon_count]; }
The vertex info field is a compound field, and could also be read as u8 values. The lower byte can be masked via vertex_info & 0xFF, and provides the number of vertices in the polygon. This must be greater than or equal to three (3), since every polygon must have at least three vertices, and therefore the vertices pointer, colours pointer, and an unknown pointer are also non-zero/non-null.
There are additionally two flags, an unknown flag masked with (vertex_info & 0x100) != 0 and the normals flag masked with (vertex_info & 0x200) != 0. The use of the unknown flag is predictably unknown. The normals flag indicates whether the polygon has normals. Additionally, whether the polygon has UVs is determined by whether the UV pointer is non-zero/non-null. It's unclear why the normals pointer doesn't do this and a flag was used.
The material index indicates which material the polygon uses. The material info is currently unknown.
After all the polygon information has been read, the polygon data is read.
The data is based on the number of vertices in the polygon (vertex count). For each polygon:
- The vertex indices are always read, which are u32 that index the mesh's vertices. Read vertex count of these.
- The normal indices are only read if the flag is set, and are u32 that index the mesh's normals. Read vertex count of these.
- The UV coordinates are only read if the UV pointer is non-zero/non-null. Each UV coordinate is two f32 (u, v). Read vertex count UVs.
- The vertex colours are always read. Each colour is three f32 (r, g, b), the same structure as
Vec3. Read vertex count colours.
With this information and the mesh information, the polygons can be reconstructed.
Nodes
Finally, the nodes block. If you thought the previous information was complex to read, the nodes turn this to eleven.
Because the node data is very complicated, I describe all nodes separately. Please refer to that document for detailed information. I will however go over how to read the data here.
In principle, this works a lot like the other blocks. The node count and node array size was given by the GameZ header. The nodes are also read in a phased manner, and also have zeroed-out nodes.
Unfortunately, to me it seems the node count is wildly inaccurate for some files. Since this seems like a memory dump, it's possible that only node count nodes should actually be read. But the nodes between count and the array size may not be zeroed out. So I resorted to reading all the node base structures until I found a zeroed out one, and then stopped. That allowed me to get the actual count.
Node base structures
Because the node count is inaccurate, a strategy is needed. Either look for the first zeroed-out nodes while reading the base structures and break out of the loop (all further nodes will be zeroed-out), or read all of them and e.g. ignore the zeroed out nodes when reading node data. To detect zeroed out nodes, a good indication is if the first byte of the name is zero (0).
In both cases, read array size node base structures.
Next, read a u32 value. For empty node types, this is the parent index (!). For other node types, this is the offset of their type-specific data in the file. For zeroed-out nodes, this is:
#![allow(unused)] fn main() { let mut expected_index = index + 1; if expected_index >= array_size { // we'll never know why??? expected_index = 0xFFFFFF; } }
And indeed, it's unclear why this isn't 0xFFFFFFFF (-1 for i32), or even 0xFFFF (-1 for i16). But that's what it is.
Optionally assert the node index rules for GameZ files:
- There can only be a single world node, and it must be the first node in the file (index 0)
- There can only be a single window node, and it must be the second node in the file (index 1)
- There can only be a single camera node, and it must be the third node in the file (index 2)
- There is at least one display node, and it must be the fourth node in the file (index 3). If there is another display node, it must be the fifth node in the file (index 4)
- There can only be a single light node, although its position in the file is variable
- Zeroed out nodes must be at the end of the array, and contiguous.
Zeroed-out nodes
Zeroed-out nodes will be all zero, except for the mesh index, which will be negative one (-1).
Node type-specific data
Then, read the type-specific data. Empty nodes do not have node data, and zeroed-out nodes don't either. Otherwise; the data is read in the same order as the base structure, based on the node type.
If a node had a non-zero parent count and/or child count on the node base structure, then these indices are read after the node's data. In the base game, these are the only nodes that have non-zero counts:
- LOD: Always one parent, always multiple children
- Object3d: Zero or one parent, sometimes children
- World: No parent, always children
But the logic could be generic simply based on the count. After the type data, the parent indices (u32) are read first, then the child indices (u32). Then the next node's type data follows.
Node relationships
As a final step, the linearly arranged nodes could be transformed into a graph/tree structure if this is more convenient.
Investigation (PM)
The data structures differ slightly for Pirate's Moon. For the main header, there is a new unknown, 32-bit integer:
#![allow(unused)] fn main() { struct HeaderPm { signature: u32, // always 0x02971222? version: u32, // always 27? unk08: u32, // new texture_count: u32, textures_offset: u32, materials_offset: u32, meshes_offset: u32, node_array_size: u32, node_count: u32, nodes_offset: u32, } }
Textures
Assumed to be the same as the base game?
Materials
Assumed to be the same as the base game, since in the mechlib they are.
Meshes
Mesh information
The mesh information has changed, and is now 100 bytes (+8):
#![allow(unused)] fn main() { struct MeshInfoPm { unk00: u32, // always 0 or 1 (bool) unk04: u32, // always 0, 1, 2 unk08: u32, parent_count: u32, // 12, always > 0 polygon_count: u32, // 16 vertex_count: u32, // 20 normal_count: u32, // 24 morph_count: u32, // 28 light_count: u32, // 32 unk36: u32, // always 0 unk40: f32, unk44: f32, unk48: u32, // always 0 polygons_ptr: u32, // 52 vertices_ptr: u32, // 56 normals_ptr: u32, // 60 lights_ptr: u32, // 64 morphs_ptr: u32, // 68 unk72: f32, unk76: f32, unk80: f32, unk84: f32, unk88: u32, // always 0 unk_count: u32, unk_ptr: u32, } }
The unk04 field (u32) used to be 0 or 1, but can now be 0, 1, or 2.
Of interest are the new fields unk_count (u32) and unk_ptr (u32). So far, we don't know what this is, but it behaves similarly to other mesh information (e.g. the vertices). If this count is zero (0), then the pointer will be null (0). Otherwise, if the count is greater than zero, the pointer will be non-null. As we will shortly see, this unknown data is 12 bytes per count (maybe a Vec3?), and read after the polygon data.
Mesh data
Next, the mesh data is read for any filled in mesh information (not zeroed-out). The offset of the start of this data should match the previously read mesh data offset, but can be read sequentially without seeking.
Reading the mesh data is dynamic, based on the counts:
- Read vertex count vertices (where each is a vector of three f32)
- Read normal count normals (where each is a vector of three f32)
- Read morph count morphs(?) (where each is a vector of three f32)
- Read the lights
- Read the polygons
- Read the unknown data, which is unknown count * 12 bytes (possibly a vector of three f32?)
#![allow(unused)] fn main() { struct Vec3 { x: f32, y: f32, z: f32, } struct Vertices { vertices: [Vec3; vertex_count], } struct Normals { normals: [Vec3; normal_count], } struct Morphs { morphs: [Vec3; morph_count], } struct Unknowns { unknowns: [Vec3, unk_count], } }
Light information and data
The light information is largely unexplored and read in two phases. First, light count light information structures are read, each of 80 bytes in size:
#![allow(unused)] fn main() { struct LightInfoPm { unk00: u32, unk04: u32, unk08: u32, extra_count: u32, unk16: u32, unk20: u32, unk24: u32, unk28: f32, unk32: f32, unk36: f32, unk40: f32, ptr: u32, unk48: f32, unk52: f32, unk56: f32, unk60: f32, unk64: f32, unk68: f32, unk72: f32, unk76: f32, } // probably good to combine lights + extras // in real code struct Lights { lights: [LightInfo; light_count], // pseudo-code: extra_count is variable! extras: [[Vec3; extra_count]; light_count], } }
The important field here is at offset 12, which is a u32 or i32 and indicates how much extra data to read. This data is read after all the light information. In this case, loop over the light information, and read extra count vertices (where each is a vector of the f32).
More research is needed on what the lights do.
Polygon information and data
The polygon information structure is 40 bytes:
#![allow(unused)] fn main() { struct PolygonInfoPm { vertex_info: u32, // always <= 0x3FF unk04: u32, // always >= 0, <= 20 vertices_ptr: u32, // always != 0 normals_ptr: u32, unk16: u32, // always 1 uvs_ptr: u32, // always != 0 colors_ptr: u32, // always != 0 unk28: u32, // always != 0 unk32: u32, // always != 0 unk36: u32, // always 0xFFFFFF00 } bitflags PolygonFlags: u32 { Unk2 = 1 << 2, Normals = 1 << 4, TriStrip = 1 << 5, } type PolygonInfosPm = [PolygonInfoPm; polygon_count]; }
Note that this structure has significantly changed from the base game.
The vertex info field is a compound field, and could also be read as u8 values. The lower byte can be masked via vertex_info & 0xFF, and provides the number of vertices in the polygon. This must be greater than or equal to three (3), since every polygon must have at least three vertices, and therefore the vertices pointer, colours pointer, and an unknown pointer are also non-zero/non-null.
The second byte can be masked via (vertex_info & 0xFF00) >> 8; this is the polygon flags. In the Mechlib, these are much better behaved than the base game.
The flag Unk2 is predictably unknown, so far no correlation to polygon data has been found. Normals indicates whether the polygon has normals data.
Finally, the newest addition is whether the polygon is a triangle strip. This was found by Skyfaller in his investigation of the Pirate's Moon data. Triangle fans so far also always require normals data. For reading the polygon information, nothing changes for a triangle strip. What does change is how the polygon faces must be constructed by programs displaying the polygon data.
The field unk04 (u32) is always greater than or equal to zero (0), and less than or equal to twenty (20).
The vertices index pointer (vertices_ptr), UV coordinate pointer (uvs_ptr), and vertex color (colors_ptr) are always non-null/non-zero. The normals index pointer is always non-null/non-zero if the normals flag is set; otherwise, it is always zero (0).
The field unk16 (u32) is always one (1). The fields unk26 (u32) and unk32 (u32) look like pointers, and are always non-null/non-zero.
The field unk36 (u32) is always 0xFFFFFF00.
Note that unlike in MechWarrior 3, the texture/material index is not present in the polygon info - it is read later.
After all the polygon information has been read, the polygon data is read.
The data is based on the number of vertices in the polygon (vertex count). For each polygon:
- The vertex indices are always read, which are u32 that index the mesh's vertices. Read vertex count of these.
- The normal indices are only read if the flag is set, and are u32 that index the mesh's normals. Read vertex count of these.
- The texture index is always read. This is a single u32.
- The UV coordinates are always read. Each UV coordinate is two f32 (u, v). Read vertex count UVs.
- The vertex colours are always read. Each colour is three f32 (r, g, b), the same structure as
Vec3. Read vertex count colours.
With this information and the mesh information, the polygons can be reconstructed.
Nodes
Unexplored.
In-game use
These models are used in-game and in the mechlab screen.
Nodes
Nodes are how the world data is organised and structured. Nodes appear in GameZ files and mechlib archives. There are eight known node types in GameZ files:
- Camera
- Display
- Empty
- Light
- LOD (level of detail)
- Object3d
- Window
- World
In MechWarrior 3, the only valid node type in the mechlib archive is Object3d. In Pirate's Moon, the only valid node types in the mechlib archive are Object3d and LOD.
We also think there are other node types from the animations:
- Sequence
- Animate or Animation
- Sound
- Switch (i.e. flow control)
Each node type has the same base structure, although some node types do not seem to use all the information in the base structure. The node types also have node-specific structures/information.
Node organisation/relationships
Each node can have several parents, and several children. In fact, each node tracks both the children and the parents, and there doesn't seem to be a way of ensuring this data is consistent other than careful coding (e.g. when a child is removed, also remove it's reference to the parent).
In principle, this results in a directed graph structure. Cycles are also absolutely possible. Again this was presumably carefully avoided because a cyclic graph is not useful for most processing. Let's assume therefore that a valid representation of nodes inside the engine is a directed acyclic graph (DAG) at the very least.
In reality, the nodes are usually tree-like, although in a "tree" in the computer science sense, there can only be one root, and each node has exactly one parent. From what I can see, this isn't necessarily the case for MW3. Otherwise, why allow a node to have multiple parents?
However, when loading nodes from the mechlib or GameZ files, the nodes indeed only have either zero (0) or one (1) parent (at load time). We'll discuss further restrictions on the different node types shortly.
Common data types
#![allow(unused)] fn main() { tuple Vec3(f32, f32, f32); tuple Color(f32, f32, f32); tuple Matrix(f32, f32, f32, f32, f32, f32, f32, f32, f32); const MATRIX_EMPTY: Matrix = Matrix(0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0); const MATRIX_IDENTITY: Matrix = Matrix(1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0); }
Node data structures
- Node data structures in the base game (MW3)
- Node data structures in the expansion (PM) (incomplete)
Node parents and children
In principle, all nodes could have multiple parents, and multiple children. In practice, no nodes have multiple parents, and as described in the node organisation and in the game-specific node data structures:
- Camera nodes don't have a parent or children
- Display nodes don't have a parent or children
- Empty nodes don't have a parent or children (at least not for the purposes of this part)
- Light nodes don't have a parent or children
- LOD nodes always have a parent, and always have children
- Object3d nodes can have a parent and children
- Window nodes don't have a parent or children
- World nodes don't have a parent, but do have children
The reason I describe this in such detail is that it helps understand how the game nodes are structured.
In the general case, both the parent and children indices are dynamic arrays. Read parent count u32 values first for the parent index/indices, and then read child count u32 values next for the child indices. (Obviously, if the count is zero, it isn't necessary to read anything.)
Node positions in the GameZ file
There are also restrictions on which nodes can appear where in a GameZ file. Mechlib archives can only contain certain nodes, so this does not apply.
When loading a GameZ file:
- There can only be a single world node, and it must be the first node in the file (index 0)
- There can only be a single window node, and it must be the second node in the file (index 1)
- There can only be a single camera node, and it must be the third node in the file (index 2)
- There is at least one display node, and it must be the fourth node in the file (index 3). If there is another display node, it must be the fifth node in the file (index 4)
- There can only be a single light node, although its position in the file is variable
- Zeroed out nodes must be at the end of the array, and contiguous.
Nodes (MW3)
Nodes are how the world data is organised and structured. Please see the general node overview first. This page describes node data structures for MechWarrior 3 only.
Node base/shared structure
This is the structure used by all nodes, and is 208 bytes in size:
#![allow(unused)] fn main() { struct NodeMw { name: [u8; 36], flags: NodeFlags, unk040: u32, // always 0 unk044: u32, zone_id: u32, node_type: NodeType, data_ptr: u32, mesh_index: i32, environment_data: u32, // always 0 action_priority: u32, // always 1 action_callback: u32, // always 0 area_partition_x: i32, // -1, or >= 0, <= 64 area_partition_y: i32, // -1, or >= 0, <= 64 parent_count: u32, // always 0 or 1 parent_array_ptr: u32, children_count: u32, children_array_ptr: u32, unk100: u32, // always 0 unk104: u32, // always 0 unk108: u32, // always 0 unk112: u32, // always 0 unk116: Box3d, unk140: Box3d, unk164: Box3d, unk188: u32, // always 0 unk192: u32, // always 0 unk196: u32, unk200: u32, // always 0 unk204: u32, // always 0 } tuple Box3d(f32, f32, f32, f32, f32, f32); enum NodeType: u32 { Empty = 0, Camera = 1, World = 2, Window = 3, Display = 4, Object3d = 5, Lod = 6, // Sequence = 7, // Animate = 8, Light = 9, // Sound = 10, // Switch = 11, } bitflags NodeFlags: u32 { // Unk00 = 1 << 0, // Unk01 = 1 << 1, Active = 1 << 2, AltitudeSurface = 1 << 3, IntersectSurface = 1 << 4, IntersectBbox = 1 << 5, // Proximity = 1 << 6, Landmark = 1 << 7, Unk08 = 1 << 8, HasMesh = 1 << 9, Unk10 = 1 << 10, // Unk11 = 1 << 11, // Unk12 = 1 << 12, // Unk13 = 1 << 13, // Unk14 = 1 << 14, Terrain = 1 << 15, CanModify = 1 << 16, ClipTo = 1 << 17, // Unk18 = 1 << 18, TreeValid = 1 << 19, // Unk20 = 1 << 20, // Unk21 = 1 << 21, // Unk22 = 1 << 22, // Override = 1 << 23, IdZoneCheck = 1 << 24, Unk25 = 1 << 25, // Unk26 = 1 << 26, // Unk27 = 1 << 27, Unk28 = 1 << 28, // Unk29 = 1 << 29, // Unk30 = 1 << 30, // Unk31 = 1 << 31, Base = Active | TreeValid | IdZoneCheck, Default = Base | AltitudeSurface | IntersectSurface, } const DEFAULT_ZONE_ID: u32 = 255; }
I'm pretty sure the name is 36 bytes long, not the usual 32 bytes and another field. Assume ASCII. The "padding" for the name is also odd. It seems like all nodes are initialised with the name to Default_node_name (padded with zeros/nulls to 36 bytes). Then, when the name is filled in, it is overwritten with the node name (zero/null terminated). This is likely not important when only reading the data, but is important when trying to write a binary-accurate replica.
Many flags are unknown in their functionality. Which flags are valid for a node also depends on the node type, and are described further in the sub-sections. The following information is invariant, i.e. does not depend on the node type.
The fields unk040, unk100, unk104, unk108, unk112, unk188, unk192, unk200, and unk204 are always zero (0).
The field environment_data is always zero (0). The field action_callback is always zero (0)/null (this is possibly a pointer). The field action_priority is always one (1).
The area partition values are tied to the world structure. These must either be both negative one (-1), which indicates no area partition is assigned to the node. Alternatively, both values must be greater than or equal to zero (0) and less than or equal to 64 (this upper bound is arbitrarily chosen based on usual area partition sizes), which indicates an area partition is assigned to the node. Once the world node data is loaded, these can be properly validated. Some node types can have stricter validation on this.
During loading, the parent count is always zero (0) or one (1). Some node types can have stricter validation on this. If the parent count is zero, then the parent array pointer is zero/null, otherwise it is non-zero/non-null. The child count is usually less than or equal to 64 (this upper bound is arbitrarily chosen based on usual child counts). Some node types can have stricter validation on this. If the child count is zero, then the child array pointer is zero/null, otherwise it is non-zero/non-null.
We currently think the fields unk116, unk140, and unk164 are values of six floating point numbers that specify a box in three dimensions. They are likely some kind of bounding boxes.
Therefore, for any node in a GameZ file, after filtering the invariant data, the variable data is the name, the flags, unk044, the zone ID, the data pointer, the mesh index, the area partition values, the parent count (i.e. whether the node has a parent) and the parent array pointer, the child count and the child array pointer, unk116, unk140, unk164, and unk196.
Camera nodes base structure
Since there can only be one camera node, the node name is always camera1. The flags will always be the default node flags. The field unk044 will always be zero (0). The zone ID will always be the default zone ID (255). Camera nodes always have data associated with them, so the data pointer will always be non-zero/non-null. The mesh index will always be negative one (-1). The area partition will always be unassigned (-1, -1). There will be no parents, and therefore the parent array pointer is zero/null. There will be no children, and therefore the child array pointer is zero/null. The fields unk116, unk140, and unk164 will always be zeros (0.0). The field unk196 will always be zero (0).
Therefore, the variable data is the data pointer.
Display nodes base structure
There can be one or two display nodes, which always have the name display. The flags will always be the default node flags. The field unk044 will always be zero (0). The zone ID will always be the default zone ID (255). Display nodes always have data associated with them, so the data pointer will always be non-zero/non-null. The mesh index will always be negative one (-1). The area partition will always be unassigned (-1, -1). There will be no parents, and therefore the parent array pointer is zero/null. There will be no children, and therefore the child array pointer is zero/null. The fields unk116, unk140, and unk164 will always be zeros (0.0). The field unk196 will always be zero (0).
Therefore, the variable data is the data pointer.
Empty nodes base structure
The field unk044 will be 1, 3, 5, or 7. The zone ID will be either one (1) or the default zone ID (255). Empty nodes don't have data associated with them, so the data pointer will always be zero/null. The mesh index will always be negative one (-1). The area partition will always be unassigned (-1, -1). There will be no parents, and therefore the parent array pointer is zero/null. There will be no children, and therefore the child array pointer is zero/null. The field unk196 will always be zero (0).
Therefore, the variable data is the name, flags, unk044, the zone ID, unk116, unk140, and unk164. Additionally, empty nodes do have a parent index, but when using a GameZ and mechlib-compatible base structure, this is stored outside the base structure. This will be discussed during loading in more detail, but it might be useful to include a field for this here.
Light nodes base structure
Since there is only one light node, the node name is always sunlight. The flags will always be the default node flags and Unk08 (0x100). The field unk044 will always be zero (0). The zone ID will always be the default zone ID (255). Light nodes always have data associated with them, so the data pointer will always be non-zero/non-null. The mesh index will always be negative one (-1). The area partition will always be unassigned (-1, -1). There will be no parents, and therefore the parent array pointer is zero/null. There will be no children, and therefore the child array pointer is zero/null. The field unk116 will always have the values (1.0, 1.0, -2.0, 2.0, 2.0, -1.0). The fields unk140 and unk164 will always be zeros (0.0). The field unk196 will always be zero (0).
Therefore, the variable data is the data pointer.
LOD nodes base structure
The field unk044 will always be one (1). The zone ID will be either the default zone ID (255), or a value greater than or equal to one (1) and less than or equal to 80 (this upper bound is arbitrarily chosen based on usual zone IDs). LOD nodes always have data associated with them, so the data pointer will always be non-zero/non-null. The mesh index will always be negative one (-1). There will be one parent, and therefore the parent array pointer is non-zero/non-null. There will be at last one child, and therefore the child array pointer is non-zero/non-null. The field unk116 will be unequal to (0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0), and the field unk164 will be equal to unk116. The field unk140 will always be zeros (0.0). The field unk196 will always be 160.
Therefore, the variable data is the name, flags, the zone ID, the data pointer, the area partition values, the parent array pointer, the child count, the child array pointer, and unk116.
Object3d nodes base structure
The field unk044 will always be one (1). The zone ID will be either the default zone ID (255), or a value greater than or equal to one (1) and less than or equal to 80 (this upper bound is arbitrarily chosen based on usual zone IDs). Object3d nodes always have data associated with them, so the data pointer will always be non-zero/non-null.
The mesh index depends on the HasMesh flag, and whether the node is in a GameZ file or a mechlib archive. For a GameZ file, the mesh index is an index. So if the flag is set, then the index is greater than or equal to zero (0). If the flag is unset, then the index is always negative one (-1). For a mechlib archive, the mesh index is actually a pointer value, since the data is already stored hierarchically. So if the flag is set, this is non-zero/non-null. If the flag is unset, this is zero/null. Note that for the non-null case, if you are loading the value as a signed integer (i32), the memory on 32-bit machines was limited. In practice, it won't be greater than 2147483647 bytes, so you can also check if the value is greater than zero.
In short:
IsMechlib && !HasMesh=>mesh_index == 0(null ptr)IsMechlib && HasMesh=>mesh_index != 0(non-null ptr)IsGameZ && !HasMesh=>mesh_index == -1(invalid index)IsGameZ && HasMesh=>mesh_index > -1(valid index)
The field unk196 will always be 160.
Therefore, the variable data is the name, flags, the zone ID, the data pointer, the area partition values, the parent count, the parent array pointer, the child count, the child array pointer, unk116, unk140, and unk164.
Window nodes base structure
Since there can only be one window node, the node name is always window1. The flags will always be the default node flags. The field unk044 will always be zero (0). The zone ID will always be the default zone ID (255). Window nodes always have data associated with them, so the data pointer will always be non-zero/non-null. The mesh index will always be negative one (-1). The area partition will always be unassigned (-1, -1). There will be no parents, and therefore the parent array pointer is zero/null. There will be no children, and therefore the child array pointer is zero/null. The fields unk116, unk140, and unk164 will always be zeros (0.0). The field unk196 will always be zero (0).
Therefore, the variable data is the data pointer.
World nodes base structure
Since there can only be one world node, the node name is always world1. The flags will always be the default node flags. The field unk044 will always be zero (0). The zone ID will always be the default zone ID (255). World nodes always have data associated with them, so the data pointer will always be non-zero/non-null. The mesh index will always be negative one (-1). The area partition will always be unassigned (-1, -1). There will be no parents, and therefore the parent array pointer is zero/null. There will be at last one child, and therefore the child array pointer is non-zero/non-null. The fields unk116, unk140, and unk164 will always be zeros (0.0). The field unk196 will always be zero (0).
Therefore, the variable data is the data pointer, the child count, and the child array pointer.
Node type data structures
All nodes except empty nodes have extra, type-specific data associated with them.
Camera data
#![allow(unused)] fn main() { struct Camera { world_index: i32, // always 0 window_index: i32, // always 1 focus_node_xy: i32, // always -1 focus_node_xz: i32, // always -1 flags: u32, // always 0 translation: Vec3, // always 0.0 rotation: Vec3, // always 0.0 world_translate: Vec3, // always 0.0 world_rotate: Vec3, // always 0.0 mtw_matrix: Matrix, // always 0.0 unk104: Vec3, // always 0.0 view_vector: Vec3, // always 0.0 matrix: Matrix, // always 0.0 alt_translate: Vec3, // always 0.0 clip_near_z: f32 clip_far_z: f32, zero184: [u8; 24], // always 0 lod_multiplier: f32, // always 1.0 lod_inv_sq: f32, // always 1.0 fov_h_zoom_factor: f32, // always 1.0 fov_v_zoom_factor: f32, // always 1.0 fov_h_base: f32, fov_v_base: f32, fov_h: f32, fov_v: f32, fov_h_half: f32, fov_v_half: f32, unk248: u32, // always 1 zero252: [u8; 60], // always 0 unk312: u32, // always 1 zero316: [u8; 72], // always 0 unk388: u32, // always 1 zero392: [u8; 72], // always 0 unk464: u32, // always 0 fov_h_cot: f32, fov_v_cot: f32, stride: i32, // always 0 zone_set: i32, // always 0 unk484: i32, // always -256 } }
The size of the camera structure is 488 bytes. This is large, but considering there is only one camera, it probably made sense to trade a bit of memory for storing intermediate results to speed up computation.
We understand a lot of the camera structure, although most of the information when loaded from a file is zeroed out, and is then initialised after loading (possibly by the interpreter).
The important fields are the near Z (f32) and far Z (f32) clipping values at offset 176, and the horizontal (f32) and vertical (f32) field of view values (FoV) at offset 232. The clipping near Z must be greater than 0.0, and the far Z must be greater than the near Z.
Many of the other FoV-related values are directly derived from the FoV. The FoV base values are equal to the FoV, because the zoom factor is one (1.0). The FoV half values are equal to the FoV divided by two (2.0). And the FoV cotangent values are derived from the cotangent of the FoV half values.
Therefore, for loading a level, the clipping and FoV values are the only important parts.
Display data
#![allow(unused)] fn main() { const CLEAR_COLOR: Color = Color( 0.3919999897480011, 0.3919999897480011, 1.0 ); struct Display { origin_x: u32, // always 0 origin_y: u32, // always 0 resolution_x: u32, // always 640 resolution_y: u32, // always 400 clear_color: Color, // always CLEAR_COLOR } }
The size of the display structure is 28 bytes.
The display data is completely constant when loading. The origin x and y values (u32 or i32) are always zero (0). The resolution x and y values (u32 or i32) are always 640 and 400, respectively. The clear colour is always 0.3919999897480011, 0.3919999897480011, and 1.0, which is a blue-ish colour (#6464ff).
Empty data
Empty nodes do not have data.
Light data
#![allow(unused)] fn main() { struct Light { direction: Vec3, translation: Vec3, // always 0.0 zero024: [u8; 112], // always 0 unk136: f32, // always 1.0 unk140: f32, // always 0.0 unk144: f32, // always 0.0 unk148: f32, // always 0.0 unk152: f32, // always 0.0 diffuse: f32, // always >= 0.0, <= 1.0 ambient: f32, // always >= 0.0, <= 1.0 color: Color, // always 1.0 flags: LightFlags, // always Default range_near: f32, // always > 0.0 range_far: f32, range_near_sq: f32, range_far_sq: f32, range_inv: f32, unk200: u32, // always 1 unk204: u32, // always != 0 // Possibly not part of the light structure unk208: u32, // always 0 } // Also used for light state events in Anim bitflags LightFlags: u32 { Inactive = 0; TranslationAbs = 1 << 0; Translation = 1 << 1; Rotation = 1 << 2; Range = 1 << 3; Color = 1 << 4; Ambient = 1 << 5; Diffuse = 1 << 6; Directional = 1 << 7; Saturated = 1 << 8; Subdivide = 1 << 9; Static = 1 << 10; Default = TranslationAbs | Translation | Range | Directional | Saturated | Subdivide; } }
The size of the light structure either 208 bytes, or 212 bytes (more on this shortly).
What's known about the light structure comes a lot from the animations. There is a vast block of the structure at offset 24 with a length of 112 bytes that is completely unknown and zeroed out.
The direction (Vec3) of the light is given. The translation (Vec3) is always zero (0.0). The diffuseness of the light (f32) is greater or equal to zero (0.0) and less than or equal to one (1.0). The ambient value (f32) is greater or equal to zero (0.0) and less than or equal to one (1.0). It isn't quite clear what this does, since the only colour in the structure is white (1.0, 1.0, 1.0). The flags indicate which members of the structure are valid, although it is always set to the default alias (TranslationAbs, Translation, Range, Directional, Saturated, and Subdivide). The near range (f32) is always greater than zero (0.0), while the far range (f32) is always greater than the near range. The squared range values are simply that, the near and far range values squared. The inverse range value is one over the range difference or delta (far minus near), so 1.0 / (range_far - range_near).
I've been told the last three fields are something to do with the light's parent. The current theory is that it is a dynamic array. The unk200 field is a count, and unk204 is an array of size count with node indices or pointers. That would make unk208 a dump of the array, and variable/not part of the light structure. If this is the case, then the light structure is 208 bytes in size. If the count is zero (0) - which it never is - then presumably the pointer would be zero/null, otherwise the pointer would be non-zero/non-null (which we do see). And then after the light structure is read, count u32 or i32 values would be read (but since count is always 1, it's only one value), which then indicates the indices of the parents. Since this is always zero (0), the light is parented to the world. This seems nuts; it isn't clear why lights don't use the default parent fields on the node base structure. It doesn't matter for MW3, but might be useful for PM. We'll also see similar indications of dynamic arrays in other structures (e.g. the world data).
LOD data
#![allow(unused)] fn main() { struct LodMw { level: u32, // always 0 or 1 range_near_sq: f32, range_far: f32, range_far_sq: f32, zero16: [u8; 44], // always 0 unk60: f32, unk64: f32, unk68: u32, // always 1 unk72: u32, // always 0 or 1 (bool) unk76: u32, } }
The size of the LOD structure is 80 bytes.
The level field (u32) is always zero (0) or one (1). Usually, this would make it a Boolean, but I think it corresponds to the level of detail setting, so e.g. low and high (hence the name). The near range value (f32) is always greater than or equal to zero (0.0) and less than or equal to 1000.0 squared, so it's assumed this is the near range squared. The far range value is stored as the base value (f32), which is always greater than zero (0.0), and why I suspect this is the far range, and as a squared value (f32). These are guesses at best.
The unk60 field (f32) is greater than or equal to zero (0.0), while the unk64 field (f32) is this value squared. The unk68 field (u32) is always one (1). The unk72 field (u32) is either zero (0) or one (1), a Boolean. If unk72 is zero/false, then the unk76 field (u32) is also zero (0). If unk72 is one/true, then the unk76 field is non-zero/non-null, which makes it likely a pointer.
Object3d data
#![allow(unused)] fn main() { struct Object3d { flags: Object3dFlags, opacity: f32, // always 0.0 unk008: f32, // always 0.0 unk012: f32, // always 0.0 unk016: f32, // always 0.0 unk020: f32, // always 0.0 rotation: Vec3, scale: Vec3, // always 1.0 rot_matrix: Matrix, translation: Vec3, zero096: [u8; 48], // always 0 } bitflags Object3dFlags: u32 { HasOpacity = 1 << 2, // 0x02 NoCoordinates = 1 << 3, // 0x08 Unk20 = 1 << 5, // 0x20 } }
The size of the Object3d structure is 144 bytes. This is a surprisingly large overhead, because there are many objects in a game world. It's also unclear why Euler angles and a matrix were used instead of Quaternions (which the motions use).
The flags (u32) are basically unknown. Only two values occur, 32 or 40. So an unknown flag (Unk20, 0x20) is always set, and then a flag I've named "NoCoordinates" (0x08) can either be set or unset. From some of the animation work and testing, it seems like there is a flag for if the object has opacity (0x02). Since this is always unset in GameZ files and mechlib archives, opacity (f32) is always zero (0.0), otherwise we can probably expect opacity to be greater or equal to zero (0.0) and less than or equal to one (1.0). There are four fields that are always zero (0.0), we don't even strictly know if they are floating point (f32) because of this.
Next follows the rotation (Vec3), presumably the scale (Vec3) which is always one (1.0), a matrix (Matrix, 3x3), and the translation (Vec3). If the no coordinates flag is set, then the rotation and translation will be zeros (0.0), and the matrix will be the identity matrix (MATRIX_IDENTITY). If the no coordinates flag is unset, then the rotation components will each be greater than or equal to negative Pi and less than or equal to positive Pi, and the translation while unspecified should be used. In most cases, the matrix can be calculated from the rotation, which is the x, y, z Euler angles:
#![allow(unused)] fn main() { fn euler_to_matrix(rotation: &Vec3) -> Matrix { let x = -rotation.0; let y = -rotation.1; let z = -rotation.2; let (sin_x, cos_x) = x.sin_cos(); let (sin_y, cos_y) = y.sin_cos(); let (sin_z, cos_z) = z.sin_cos(); // optimized m(z) * m(y) * m(x) Matrix( cos_y * cos_z, sin_x * sin_y * cos_z - cos_x * sin_z, cos_x * sin_y * cos_z + sin_x * sin_z, cos_y * sin_z, sin_x * sin_y * sin_z + cos_x * cos_z, cos_x * sin_y * sin_z - sin_x * cos_z, -sin_y, sin_x * cos_y, cos_x * cos_y, ) } }
In 2% of all Object3d nodes, this calculation is slightly off. This seems like either a bug or inaccuracy in the written data.
An additional trap for bit-perfect gamez.zbd writing is that negative zero (-0.0) and positive zero (+0.0) floating point values have different bit patterns per IEEE 754. And -0.0 is equal to 0.0. So for bit-perfect round-tripping, it is necessary to preserve the zero signs, even in the case where the no coordinates flag is set.
Window data
#![allow(unused)] fn main() { struct Window { origin_x: u32, // always 0 origin_y: u32, // always 0 resolution_x: u32, // always 320 resolution_y: u32, // always 200 zero016: [u8; 212], // always 0 buffer_index: i32, // always -1 buffer_ptr: u32, // always 0 unk236: u32, // always 0 unk240: u32, // always 0 unk244: u32, // always 0 } }
The size of the Window structure is 248 bytes.
The origin x (u32) and y (u32) are always set to zero (0). The resolution x (u32) and y (u32) are always set to 320 and 200, respectively. Observant readers will note this is half the default display node resolution. Most of the rest of the structure from offset 16 with a length of 212 bytes is zero. The next non-zero value is at offset 228, which is what we think is the buffer index (i32), and is always negative one (-1). The next field is the buffer pointer, and this is always zero/null. Finally, the next three values (e.g. u32) are all zero (0).
World data
#![allow(unused)] fn main() { struct World { unk000: u32, // always 0 area_partition_used: u32, // always 0 area_partition_count: u32, area_partition_ptr: u32, fog_state: u32, // always 1 fog_color: Color, // always 0.0 fog_range_near: f32, // always 0.0 fog_range_far: f32, // always 0.0 fog_altitude_high: f32, // always 0.0 fog_altitude_low: f32, // always 0.0 fog_density: f32, // always 0.0 area_left: f32, area_bottom: f32, area_width: f32, area_height: f32, area_right: f32, area_top: f32, unk076: u32, // always 16 virtual_partition: u32, // always 1 virt_partition_x_min: u32, // always 1 virt_partition_y_min: u32, // always 1 virt_partition_x_max: u32, virt_partition_y_max: u32, virt_partition_x_size: f32, // always +256.0 virt_partition_y_size: f32, // always -256.0 virt_partition_x_half: f32, // always +128.0 virt_partition_y_half: f32, // always -128.0 virt_partition_x_inv: f32, // always 1.0 / +256.0 virt_partition_y_inv: f32, // always 1.0 / -256.0 virt_partition_diag: f32, // always -192.0 partition_inclusion_tol_low: f32, // always 3.0 partition_inclusion_tol_high: f32, // always 3.0 virt_partition_x_count: u32, virt_partition_y_count: u32, virt_partition_ptr: u32, unk148: f32, // always 1.0 unk152: f32, // always 1.0 unk156: f32, // always 1.0 unk160: u32, // always 1 unk164: u32, // always != 0 unk168: u32, // always != 0 unk172: u32, // always 0 unk176: u32, // always 0 unk180: u32, // always 0 unk184: u32, // always 0 unk188: u32, } }
The size of the World structure is 188 or 192 bytes.
World structure
The first field unk000 (u32) is always zero (0).
The area partition information is partially derived from later fields. At load time, the used count (u32) is always zero (0). The count (u32) can be validated later, from the virtual partition information. The pointer (u32) is always non-zero/non-null.
The fog state (u32) is always one (1), which corresponds to a linear fog. Exponential fog is two (2), but is never set. The fog colour is always zero/black (0.0, 0.0, 0.0). The fog near and far range values (f32) and the fog altitude high and low values (f32) are always zero (0.0), as well as the fog density (f32). This can be set by the interpreter when loading the world, or by the corresponding anim.zbd.
The area values describe the area of the game world. Although these are floating point numbers, they are truncated, and can be converted to integers. The right coordinate must be larger than the left coordinate, and the bottom coordinate must be larger than the top. The width and height can be calculated from the right/left and top/bottom values, respectively.
The field unk076 (u32) is always 16.
The virtual partition information is fairly regular. It's not clear why this is called "virtual partition", except that the interpreter has a commands. For example, WorldSetVirtualPartition on, which is why the virtual partition field (u32) is always one (1). The minimum x and y values (u32) are always one (1). The maximum x and y values (u32) give the partition size. The x size (f32) is always 256.0, and the y size (f32) is always -256.0. The half x size (f32) is predictably 128.0, and the half y size is -128.0. The inverse x size (f32) is 1.0 / 256.0, and the inverse y size (f32) is 1.0 / -256.0. The partition diagonal half size is always -192.0. It's a bit of an odd calculation: likely the square root of the x and y size divided by two (2.0), or alternatively times 0.5. But if the x and y size are actually used, it comes out as -181.0. As far as I can see, this is a result of a poor square root approximation that a is well-known bit hack. For example, I have found it referenced in a paper named "A benchmark for C program verification" (arXiv:1904.01009v1), or in a thread from 2014 titled "Floating Point Hacks" on the dark bit factory forums. Here is a reproduction of the paper's C code:
float
sqrt_approx(float x)
{
union { float x; unsigned i; } u;
u.x = x;
u.i = (u.i >> 1) + 0x1fc00000;
return u.x;
}
Translated to Rust:
fn approx_sqrt(value: f32) -> f32 { let cast = i32::from_ne_bytes(value.to_ne_bytes()); let approx = (cast >> 1) + 0x1FC00000; f32::from_ne_bytes(approx.to_ne_bytes()) } fn main() { let x_size = 256.0f32; let y_size = -256.0f32; let size = x_size * x_size + y_size * y_size; let diag_good = size.sqrt() * 0.5; let diag_poor = approx_sqrt(size) * 0.5; println!("{} {}", diag_good, diag_poor); }
This prints 181.01933 and 192, respectively, so a good fit. It isn't clear why an approximate square root was needed here (what's the speed reason?). But we will see this approximate square root function in the partition code later.
The partition inclusion low and high tolerance (f32) are always three (3.0), this also matches the values set in interp.zbd.
The virtual partition x count (u32) is the number of steps from area left to area right in y size (256) steps or increments, so roughly (area_right - area_left) / 256 (this may need to be rounded up). The virtual partition y count (u32) is the number of steps from area bottom to area top in y size (-256) steps/increments. This is therefore inverted! So roughly (area_top - area_bottom) / -256 (this may need to be rounded down?). Also, the virtual partition x max is equal to the virtual partition x count minus one (1), and the virtual partition y max is equal to the virtual partition y count minus one (1).
The virtual partition total count (not part of the structure) can also now be calculated, and the area partition count will be equal to this, except for the T1 world (the training), where it is the count minus one (1).
The virtual partition pointer (u32) is always non-zero/non-null. The fields unk148, unk152, and unk156 (f32) are always one (1.0).
The field unk160 (u32) is always one (1), and the fields unk164 and unk168 (u32) are always non-zero/non-null - likely pointers. The fields unk172, unk176, unk180, and unk184 (u32, maybe) are always zero (0). Finally, the field unk188 (u32) is variable.
Just like the lights structure, it seems like the fields unk160, unk164, unk168, and possibly unk172 could be dynamic arrays. This would make the world structure 188 bytes, and then e.g. unk160 indicates how many values to read.
In short, the variable data is the area partition count and pointer, the area (although only 4 values are needed), the virtual partition x and y counts (since the maximum extent can be calculated from this), the virtual partition pointer, and the fields unk164, unk168, and unk188.
The area ranges (left to right, bottom to top) are also needed to read the partitions.
World partitions
The partitions depend on the area. Specifically, partitions are read in a nested loop, roughly:
#![allow(unused)] fn main() { let mut y = area_bottom; while y >= area_top { let mut x = area_left; while x <= area_right { read_partition(x, y); x += 256; } y += -256; } }
I'm not 100% sure the maths is correct, but you get the idea.
#![allow(unused)] fn main() { struct Partition { unk00: i32, // always 256/0x100 unk04: i32, // always -1 part_x: f32, // always x part_y: f32, // always y x_min: f32, // always x z_min: f32, y_min: f32, // always y + -256.0 x_max: f32, // always x + 256.0 z_max: f32, y_max: f32, // always y x_mid: f32, // always x + 128.0 z_mid: f32, y_mid: f32, // always y + -128.0 diagonal: f32, unk56: u16, // always 0 count: u16, ptr: u32, unk64: u32, // always 0 unk68: u32, // always 0 } }
The size of a partition structure is 72 bytes.
The first field (i32?) could be the partition x size, but could also be bit flags. It is always 256/0x100. The second field (i32) is always negative one (-1), so this could be the partition y scaling. It's just an odd way to store this information.
The partition x and y are the same as the area x and y from the loop, but as floating point numbers.
The next fields give the minimum, maximum, and mean x, z, and y values (all f32). Because of the step values, x_min is always equal to x, and y_min is always equal to y + -256.0 (or y - 256.0). x_max is always equal to x + 256.0, and y_max is always equal to y. I am not sure how z_min or z_max is determined, possibly from the geometry of the partition.
Therefore, the mid-points can easily be calculated. First, division is usually avoided, especially on old CPUs, since it was slower than multiplication. We can write x / 2.0 as x * 0.5. The average is then (max + min) * 0.5. The x and y calculations simplify further.
Since x_min = x and x_max = x + 256.0:
x_mid = (x_max + x_min) * 0.5x_mid = (x_min + x_max) * 0.5x_mid = (x + (x + 256.0)) * 0.5x_mid = (2.0 * x + 256.0) * 0.5x_mid = x + 128.0
Since y_min = y + -256.0 and y_max = y:
y_mid = (y_max + y_min) * 0.5y_mid = (y + (y + -256.0)) * 0.5y_mid = (2.0 * y + -256.0) * 0.5y_mid = y + -128.0
Obviously, simplification isn't possible for z_mid, because z_min and z_max are derived from the geometry. z_mid is even more frustrating though:
#![allow(unused)] fn main() { let z_mid = (z_max + z_min) * 0.5; }
If we attempt the calculation with single-precision floating point, out of the total 22016 partitions from all versions, 21812 match this exactly, and 204 do not match exactly, only closely. I've seen another formulation of the average calculation that is rumoured to help with accuracy, but this is disputed (see "Rounding error in computing average" from StackOverflow).
#![allow(unused)] fn main() { let z_mid = z_min + (z_max - z_min) * 0.5; }
This is actually worse, failing in 2068 cases. Only when using double-precision does it produce the same result. The previous calculation does not change when using double-precision.
For most use-cases, this doesn't really matter, although it does affect the diagonal calculation, which is the next field (f32). Effectively, this is the square root of the square of the sides:
#![allow(unused)] fn main() { let x_side = (x_max - x_min) * 0.5; let z_side = (z_max - z_min) * 0.5; let y_side = (y_max - y_min) * 0.5; let diagonal = (x_side * x_side + z_side * z_side + y_side * y_size).sqrt(); }
Naturally, x_side simplifies to 128.0, and y_size to -128.0, although due to the squaring the sign does not matter. Also note that because of the squaring, any error in z_side compounds quickly, so I've found it necessary to cast z_max and z_min to f64, and perform the entire calculation up to the square root as double-precision:
#![allow(unused)] fn main() { let z_side = (z_max as f64 - z_min as f64) * 0.5; let temp = 2.0 * 128.0 * 128.0 + z_side * z_side; }
But this is where it gets silly. The partitions also use the (poor) approximate square root discussed above for the world structure (approx_sqrt). So all the precision is "lost", although it is still required to produce the same result in my testing.
Moving on, the field unk56 (u16) is always zero (0), and the fields unk64 and unk68 (u32) are also always zero (0).
The count and pointer fields are part of a dynamic array. If the count is zero (0), then the pointer is zero/null. If the count is greater than zero, then the pointer is non-zero/non-null. In this case, read count u32 values after the structure. These should be indices of nodes in the given partition.
Nodes (PM)
Nodes are how the world data is organised and structured. Please see the general node overview first. This page describes node data structures for Pirate's Moon only. Refer also to MechWarrior 3 nodes.
Node base/shared structure
Only analysed in the mechlib.
This is the structure used by all nodes, and is 208 bytes in size. Please note that while this is the same size as NodeMw, the layout is different! Refer to the base game for any other types.
#![allow(unused)] fn main() { struct NodePm { name: [u8; 36], flags: NodeFlags, unk040: u32, // always 0 unk044: u32, zone_id: u32, // always 255 (mechlib only?) node_type: NodeType, data_ptr: u32, mesh_index: i32, environment_data: u32, // always 0 action_priority: u32, // always 1 action_callback: u32, // always 0 area_partition_x: i32, // -1, or >= 0, <= 64 area_partition_y: i32, // -1, or >= 0, <= 64 parent_count: u16, // always 0 or 1 children_count: u16, parent_array_ptr: u32, children_array_ptr: u32, unk096: u32, // always 0 unk100: u32, // always 0 unk104: u32, // always 0 unk108: u32, // always 0 unk112: u32, // 0, 1, 2 (mechlib?) unk116: Box3d, unk140: Box3d, unk164: Box3d, unk188: u32, // always 0 unk192: u32, // always 0 unk196: u32, // always 0x000000A0 (mechlib?) unk200: u32, // always 0 unk204: u32, // always 0 } }
Preliminary analysis of nodes in the mechlib indicates this data structure is largely the same as the base game. The biggest change is around offset 84:
- parent_count: u32, // always 0 or 1
- parent_array_ptr: u32,
- children_count: u32,
- children_array_ptr: u32,
+ parent_count: u16, // always 0 or 1
+ children_count: u16,
+ parent_array_ptr: u32,
+ children_array_ptr: u32,
+ unk096: u32, // always 0
I.e. the parent_count and children_count have been changed from u32 values to u16 values. This has shifted the parent and child array pointers, and has introduced an extra field, unk096 (u32), which is always zero (0).
Additionally, the field unk112 (u32) is now variable, but always 0, 1, or 2.
Camera nodes base structure
Not analysed yet.
Display nodes base structure
Not analysed yet.
Empty nodes base structure
Not analysed yet.
Light nodes base structure
Not analysed yet.
LOD nodes base structure
Preliminary analysis of nodes in the mechlib indicates LOD nodes always have the node flags:
BASEUNK08UNK10ALTITUDE_SURFACEINTERSECT_SURFACEUNK25
The field unk044 will always be one (1).
The zone ID will be the default zone ID (255), but this is probably down to the mechlib. Assuming the same behaviour as the base game, the zone ID will be either the default zone ID (255), or a value greater than or equal to one (1) and less than or equal to 80 (this upper bound is arbitrarily chosen based on usual zone IDs).
LOD nodes always have data associated with them, so the data pointer will always be non-zero/non-null.
Although LOD nodes cannot have a mesh, the mesh index does depend on whether the node is in a GameZ file or a mechlib archive. For a GameZ file, the mesh index is an index, so it is always negative one (-1). For a mechlib archive, the mesh index is actually a pointer value, since the data is already stored hierarchically. So it is always zero (0). See Object3d nodes for mode information.
There will be one parent, and therefore the parent array pointer is non-zero/non-null. There will be at last one child, and therefore the child array pointer is non-zero/non-null.
The fields unk116 and unk140 will always be zeros (0.0). The field unk164 will be unequal to (0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0).
The field unk112 will always be 2. The field unk196 will always be 160.
Object3d nodes base structure
The field unk044 will be either 1 or 45697.
The zone ID will be the default zone ID (255), but this is probably down to the mechlib. Assuming the same behaviour as the base game, the zone ID will be either the default zone ID (255), or a value greater than or equal to one (1) and less than or equal to 80 (this upper bound is arbitrarily chosen based on usual zone IDs).
Object3d nodes always have data associated with them, so the data pointer will always be non-zero/non-null.
The mesh index depends on the HasMesh flag, and whether the node is in a GameZ file or a mechlib archive. For a GameZ file, the mesh index is an index. So if the flag is set, then the index is greater than or equal to zero (0). If the flag is unset, then the index is always negative one (-1). For a mechlib archive, the mesh index is actually a pointer value, since the data is already stored hierarchically. So if the flag is set, this is non-zero/non-null. If the flag is unset, this is zero/null. Note that for the non-null case, if you are loading the value as a signed integer (i32), the memory on 32-bit machines was limited. In practice, it won't be greater than 2147483647 bytes, so you can also check if the value is greater than zero.
In short:
IsMechlib && !HasMesh=>mesh_index == 0(null ptr)IsMechlib && HasMesh=>mesh_index != 0(non-null ptr)IsGameZ && !HasMesh=>mesh_index == -1(invalid index)IsGameZ && HasMesh=>mesh_index > -1(valid index)
The field unk196 will always be 160.
Other fields have not been analysed in detail, since they are liable to change outside the Mechlib.
Window nodes base structure
Not analysed yet.
World nodes base structure
Not analysed yet.
Node type data structures
All nodes except empty nodes have extra, type-specific data associated with them.
Camera data
Not analysed yet.
Display data
Not analysed yet.
Empty data
Not analysed yet.
Light data
Not analysed yet.
LOD data
Only analysed in the mechlib.
#![allow(unused)] fn main() { struct LodPm { level: u32, // always 0 or 1 range_near_sq: f32, range_far: f32, range_far_sq: f32, zero16: [u8; 44], // always 0 unk60: f32, // always == 0.0 unk64: f32, // always >= 0.0 unk68: f32, // always == unk64 * unk64 unk72: f32, // always >= 0.0 unk76: f32, // always == unk72 * unk72 unk80: u32, // always 1 unk84: u32, // always 0 unk88: u32, // always 0 } }
The size of the LOD structure is 92 bytes.
The level field (u32) is always zero (0) or one (1). Usually, this would make it a Boolean, but I think it corresponds to the level of detail setting, so e.g. low and high (hence the name). The near range value (f32) is always greater than or equal to zero (0.0) and less than or equal to 1000.0 squared, so it's assumed this is the near range squared. The far range value is stored as the base value (f32), which is always greater than zero (0.0), and why I suspect this is the far range, and as a squared value (f32). These are guesses at best.
The unk60 field (f32) is always zero (0.0). The unk64 field (f32) is greater than or equal to zero (0.0), while the unk68 field (f32) is this value squared. . The unk72 field (f32) is greater than or equal to zero (0.0), while the unk76 field (f32) is this value squared. The unk80 field (u32) is always one (1). The unk84 field (u32) and unk88 field (u32) are both always zero (0).
Object3d data
Only analysed in the mechlib.
This seems to be the same as the base game.
Window data
Not analysed yet.
World data
Not analysed yet.
Animation definition files
Animation definition files (anim files) hold compiled animation definitions for a game world.
The initial animation definitions are in the reader archives, but they are quite free form and so probably complicated and slow to parse. I think this proved so slow that load times were unacceptable, and the solution the development team came up with was to load the reader files into the engine, and then dump out the in-memory representations of the parsed animation definitions.
It isn't known - because it hasn't been investigated - if the release version is capable of loading the animation definitions from the readers directly, or how to trigger this (for example, by removing the anim.zbd files).
Investigation (MW3)
Header and TOC
Anim files begin with a simple header:
#![allow(unused)] fn main() { struct Header { signature: u32, // always 0x08170616 version: u32, // always 39 entry_count: u32, } }
The signature (u32) is the magic number 0x02971222. The version (u32) is always 39, which is different from the mechlib archives and GameZ files version. The entry count (u32) indicates how many animation definitions reader files are in the TOC that follows. This basically a list of the raw animation definition file paths:
#![allow(unused)] fn main() { struct Entry { path: [u8; 80], unk80: u32, } type Entries = [Entry; entry_count]; }
The path is an ASCII-encoded, zero-terminated string of up to 80 bytes. It is usually a relative path pointing to a .zrd file, such as ..\data\common\zrdr\commonAnim.zrd (backslashes not escaped). Again, this points to a close connection to the various reader archives, which include matching files. Please note that the path data may occasionally contain non-zero bytes after the zero-termination, for example:
00000000 2e 2e 5c 64 61 74 61 5c 63 6f 6d 6d 6f 6e 5c 7a |..\data\common\z|
00000010 72 64 72 5c 63 6f 6d 6d 6f 6e 41 6e 69 6d 2e 7a |rdr\commonAnim.z|
00000020 72 64 00 02 90 02 3e 02 90 3d 3e 02 20 3e 3e 02 |rd....>..=>. >>.|
00000030 50 3e 3e 02 c8 bb 01 02 00 ff ff ff 04 02 00 00 |P>>.............|
00000040 00 00 00 00 c0 41 3e 02 d0 41 3e 02 90 43 3e 02 |.....A>..A>..C>.|
00000050 6a d8 95 37 |j..7|
Bytes from 0x00 (0) to 0x22 (34, exclusive) are the path, byte 0x22 (34) is the zero terminator, bytes from 0x23 (36) to 0x50 (80, exclusive) is garbage data from overwritten memory, and the four bytes from 0x50 (80) to 0x54 (84, exclusive) is an unknown integer (u32?). Given that for many entries, the trailing data is zero, it seems like this memory wasn't zeroed out properly in some cases.
Animation definitions information
Following the TOC, there is some kind of information or book-keeping structure:
#![allow(unused)] fn main() { struct Info { unk00: u32, // always 0 unk04: u32, // always 0 unk08: u16, // always 0 count: u16, unk12: u32, // always != 0, ptr? unk16: u32, // always 0 unk20: u32, // always 0 unk24: u32, // always != 0, ptr? gravity: f32, unk32: u32, // always 0 unk36: u32, // always 0 unk40: u32, // always 0 unk44: u32, // always 0 unk48: u32, // always 0 unk52: u32, // always 0 unk56: u32, // always 0 unk60: u32, // always 1 unk64: u32, // always 0 } const GRAVITY: f32 = -9.8; }
Most of the structure is zeroes, except for:
- The animation count (u16) at offset 10, which is greater than zero
- The two u32 values at offset 12 and 24, which are probably pointers and non-zero/non-null
- A f32 value at offset 28, which seems to be the gravity (of the world?) used for animation calculations, but is always set to -9.8 (0xC11CCCCD; or bytes 0xCD 0xCC 0x1C 0xC1).
Animation definition structures
I'll describe the structures in full, before describing how to read animation definitions. The base animation definition structure is 316 bytes:
#![allow(unused)] fn main() { struct AnimDef { anim_name: [u8; 32], name: [u8; 32], anim_ptr: u32, // always != 0 anim_root: [u8; 32], anim_root_ptr: u32, unk104: [u8; 44], // always 0 flags: AnimDefFlags, unk152: u8, // always 0 activation: AnimActivation, unk154: u8, // always 4 unk155: u8, // always 2 exec_by_range_min: f32, exec_by_range_max: f32, reset_time: f32, unk168: f32, // always 0 max_health: f32, cur_health: f32, unk180: u32, // always 0 unk184: u32, // always 0 unk188: u32, // always 0 unk192: u32, // always 0 sequence_definitions_ptr: u32, reset_state: SequenceDefinition, sequence_definition_count: u8, object_count: u8, node_count: u8, light_count: u8, puffer_count: u8, dynamic_sound_count: u8, static_sound_count: u8, unknown_count: u8, // always zero activ_prereq_count: u8, activ_prereq_min_to_satisfy: u8, anim_ref_count: u8, unk275: u8, // always 0 objects_ptr: u32, nodes_ptr: u32, lights_ptr: u32, puffers_ptr: u32, dynamic_sounds_ptr: u32, static_sounds_ptr: u32, unknown_ptr: u32, activ_prereqs_ptr: u32, anim_refs_ptr: u32, unk312: u32, // always 0 } bitflags AnimDefFlags: u32 { ExecutionByRange = 1 << 1; ExecutionByZone = 1 << 3; HasCallbacks = 1 << 4; ResetTime = 1 << 5; NetworkLogSet = 1 << 10; NetworkLogOn = 1 << 11; SaveLogSet = 1 << 12; SaveLogOn = 1 << 13; AutoResetNodeStates = 1 << 16; ProximityDamage = 1 << 20; } enum AnimActivation: b8 { WeaponHit = 0, CollideHit = 1, WeaponOrCollideHit = 2, OnCall = 3, OnStartup = 4, } }
This is going to get complicated.
The first field is called "animation name" in the reader files, and is a 32 bytes, zero-terminated ASCII string with possible un-zeroed memory after the terminator. The second field is called simply "name" in the reader files, and is a 32 bytes, zero-terminated ASCII string (although this seems to only have zeros after the terminator). The next field is some kind of pointer (u32), possibly pointing to the engine-internal animation structure, and always non-zero/non-null. The third name is what I've called the "animation root". This is also a 32 bytes, zero-terminated ASCII string with possible un-zeroed memory after the terminator, and seems to be related to the object or node the animation is applied to. The next field is some kind of pointer (u32), possibly pointing to the engine-internal animation root, and always non-zero/non-null.
From what I could determine, if the .flt extension is stripped from the name, then if this matches the animation root name, the animation root pointer and animation pointer will be equal; otherwise, the animation root pointer and animation pointer will be unequal.
There are 44 zero bytes from offset 104 to 148 (exclusive).
At offset 148 are the flags, which indicate which optional features/values/fields the animation definition uses. I know of 10 of these:
- Execution by range (
EXECUTION_BY_RANGEin reader files), likely that the animation definition is triggered if something (only the player?) is within range. Associated with two fields. If execution by range is set, execution by zone isn't set. - Execution by zone (
EXECUTION_BY_ZONEin reader files), a very uncommon trigger only appearing eleven times in all reader files. It isn't known how this works, since in the reader files the value to this key is an empty list. If execution by zone is set, execution by range isn't set. - Has callbacks, set if any of the animation definition's sequences include a callback sequence event; otherwise unset (so this is derived, and not explicitly mentioned in the reader files). Probably to speed up callback look-ups?
- Reset time, likely whether the animation has a reset time. Definitely associated with one field, maybe two.
- Network log set and network log on. These work in tandem. In the reader files, if the
NETWORK_LOGkey is present, the "set" flag is set and the "on" flag is valid. The "on" flag is set if theNETWORK_LOGvalue isON; if it isOFFthe flag is unset. If the "set" flag isn't set, then the "on" flag isn't be set. These flags seem to control whether an animation definition is considered for transmission in a network/multiplayer game, and if it sent. - Save log set and save log on. Similar to the network flags, these work in tandem. In the reader files, if the
SAVE_LOGkey is present, the "set" flag is set and the "on" flag is valid. The "on" flag is set if theSAVE_LOGvalue isON; if it isOFFthe flag is unset. If the "set" flag isn't set, then the "on" flag isn't be set. These flags seem to control whether an animation definition is considered for inclusion in a save game file, and if it is saved. - Auto reset node states, or
AUTO_RESET_NODE_STATESin the reader files might control whether the animation nodes or animation root is reset when the animation is reset or not. This seems to be the default behaviour, as the keyAUTO_RESET_NODE_STATESis mostly followed by the valueOFFin reader files. - Proximity damage (
PROXIMITY_DAMAGEin the reader files) is uncommon, and used 22 times in the reader files. The key has a value in the reader files, but it is always 0, so I haven't been able to confirm an associated field in the structure.
The field at offset 152 is unknown (u8), and is always zero (0). Next is the animation activation (ACTIVATION in the reader files), which can be:
WEAPON_HIT, rare, 28 occurrencesCOLLIDE_HIT, uncommon, 119 occurrencesWEAPON_OR_COLLIDE_HIT, uncommon, 108 occurrencesON_CALL, most common, 3026 occurrencesON_STARTUP, rare, 58 occurrences
The field at offset 154 is unknown (u8), and is always four (4). It could be related to a concept in the engine called action priority, but this isn't sure. The field at offset 155 is unknown (u8), and is always two (2).
The next two fields are the execution by range minimum (f32) and maximum (f32) range. If the execution by range flag is set, the minimum value is greater than or equal to 0.0 and the maximum value is greater than or equal to the minimum value; otherwise both values are zero (0.0).
Next is the reset time (f32). If the reset time flag is set, this value seems to range from -1.0 to 4.0 (-1.0, 0.0, 0.3, 0.65, 0.714, 1.0, 2.0, 3.0, 4.0). If the flag is unset, this value is always negative one (-1.0). This is followed by an unknown value, which I have typed as f32 based on the surrounding values, even though it could be anything. It is always zero (0.0). Interestingly in the reader files, there is at least one instance of a RESET_TIME key with two values. It could also track the "current" animation time - whatever that is.
The maximum health value (f32) is greater than or equal to zero (0.0), while the current health value (f32) is equal to the maximum. So these could be swapped. The reader files only mention HEALTH.
The next four fields (u32/i32/f32) are always zero (0).
I'll talk more about the sequence definition pointer value (u32) when discussing the sequence definitions. This is always non-zero/non-null, but then all animation definitions have at least one sequence definition.
Next follows the reset state sequence definition (thanks Skyfaller for the analysis). This will be read later separately again (see reset sequence). This might seem odd, but the reset state can contain a variable number of events, and so must be read after the animation definition. Likely they just used the generic sequence definition serialisation/deserialisation functions here, so the data is duplicated.
Several counts of things associated with the animation definition follow. They are all u8 values:
- The number of sequence definitions
- The number of objects (Object3d nodes)
- The number of other nodes
- The number of lights
- The number of puffers
- The number of dynamic sounds
- The number of static sounds
- The number of an unknown thing, always zero (0)
- The number of activation prerequisite conditions
- The minimum number of activation prerequisites necessary for activation, either 0, 1, or 2 in the files, but could be higher. Has to be less than or equal to the number of conditions.
- The number of animation references
- Likely a padding byte at offset 275, always zero (0)
These are immediately followed with pointers for these things (u32), except for the sequence definitions (this pointer was at offset 196):
- The objects array pointer
- The nodes array pointer
- The lights array pointer
- The puffers array pointer
- The dynamic sounds array pointer
- The static sounds array pointer
- The unknown things array pointer, always zero (0)
- The activation prerequisite conditions array pointer
- The animation references array pointer
As a general rule, if the count is zero (0), then the pointer will be zero/null; otherwise, the pointer will be non-zero/non-null. These also trigger extra reads.
The final field at offset 312 (u32/i32) is unknown, and is always zero (0).
Animation definition reading
Animation definitions are read sequentially. The number of animation definitions to read was provided in the info structure. Also, when reading the animation definition array, the first item will always be zeroed out. This is a common occurrence for dynamic arrays in the anim file. Except not quite in this case! Field 153, the activation value won't be zero (0), but instead five (5), which corresponds to the on call activation.
After each animation definition structure is read, further reads based on the counts can be triggered (described in the following sections). This is also the case for the zeroed out item! It also has a zeroed out reset state!
Object3d nodes
If the object count was greater than zero, the object array is read. Each item is a 96 byte structure. When reading the array, the first item will always be zeroed out.
#![allow(unused)] fn main() { struct ObjectRef { name: [u8; 36], unk36: [u8; 60], } }
The name is a node name for a Object3d node, and so is 36 bytes long. Assume ASCII. The "padding" for the name is also odd. It seems like all nodes are initialised with the name to Default_node_name (padded with zeros/nulls to 36 bytes). Then, when the name is filled in, it is overwritten with the node name (zero/null terminated).
I haven't been able to figure out what the rest of the data (60 bytes) does.
Other nodes
If the nodes count was greater than zero, the nodes array is read. Each item is a 40 byte structure. When reading the array, the first item will always be zeroed out.
#![allow(unused)] fn main() { struct NodeRef { name: [u8; 36], pointer: u32, } }
The name is a node name for a node, and so is 36 bytes long. Assume ASCII. The "padding" for the name is also odd. It seems like all nodes are initialised with the name to Default_node_name (padded with zeros/nulls to 36 bytes). Then, when the name is filled in, it is overwritten with the node name (zero/null terminated).
The pointer (u32) is always non-zero/non-null, except for the first item.
Light nodes
If the lights count was greater than zero, the lights array is read. Each item is a 44 byte structure. When reading the array, the first item will always be zeroed out. This structure is also used for other things.
#![allow(unused)] fn main() { struct ThingRef { name: [u8; 36], pointer: u32, unk40: u32, // always 0 } }
The name is a node name for a node, and so is 36 bytes long. Assume ASCII. The "padding" for the name is also odd. It seems like all nodes are initialised with the name to Default_node_name (padded with zeros/nulls to 36 bytes). Then, when the name is filled in, it is overwritten with the node name (zero/null terminated).
The pointer (u32) is always non-zero/non-null, except for the first item. The unknown field (u32?) is always zero (0).
Puffer nodes?
If the puffer count was greater than zero, the puffer array is read. Each item is a 44 byte structure. When reading the array, the first item will always be zeroed out.
#![allow(unused)] fn main() { struct PufferRef { name: [u8; 32], unk32: u32, pointer: u32, unk40: u32, // always 0 } }
Since puffers don't seem to be nodes, the name is 32 bytes long. Assume ASCII. The name is padded/filled with zeros after the zero terminator.
The first unknown field (u32) is very strange. The lower three bytes are always zero (0), so unk32 ^ 0x00FFFFFF == 0. The high byte is sometimes non-zero.
The pointer (u32) is always non-zero/non-null, except for the first item. The second unknown field (u32?) is always zero (0).
Dynamic sounds/sound nodes
If the dynamic sounds count was greater than zero, the dynamic sounds array is read. Each item is a 44 byte structure. When reading the array, the first item will always be zeroed out. This is the same structure used by the lights.
Static sounds
If the static sounds count was greater than zero, the static sounds array is read. Each item is a 36 byte structure. When reading the array, the first item will always be zeroed out.
#![allow(unused)] fn main() { struct StaticSoundRef { name: [u8; 32], unk32: u32, // always 0 } }
Since static sounds don't seem to be nodes, the name is 32 bytes long. Assume ASCII. The name is not cleanly zero-filled after the zero terminator. The unknown field (u32) is always zero (0).
Unknown items
Since the unknown count is always zero, this is never read. I presume - based on the other fields/ordering - that it would be read here. Since no such items are read, I don't know what structure this might have.
Activation prerequisite conditions
If the animation prerequisite conditions (APC) count was greater than zero, the APC array is read. Each item is a 48 byte structure. Unlike other arrays, the first item is not zeroed out!
This is by far the most complicated to read. There are essentially three types of APCs. Based on the type, the data read is interpreted differently (i.e. it has the same size, but different types/layout). Let me first describe the opaque layout:
#![allow(unused)] fn main() { // APC = Activation prerequisite condition struct Apc { optional: u32, // always 0 or 1 (bool) type: ApcType, type_dependent: [u8; 40], } enum ApcType: u32 { Animation = 1, Object = 2, Parent = 3, } }
The optional field (u32) is always zero (0) or one (1), a Boolean, and signifies whether the APC is required or optional for activation. Animation-type APCs seem to be always required, i.e. not optional. The type field (u32) is an enumeration, where:
- One (1) means the data is interpreted as a animation-type APC
- Two (2) means the data is interpreted as an object-type APC
- Three (3) means the data is interpreted as an object-type APC in the parent role
Next, the type dependent data:
#![allow(unused)] fn main() { struct ApcAnim { name: [u8; 32], unk32: u32, // always 0 unk36: u32, // always 0 } struct ApcObject { active: u32, // always 0 or 1 (bool) name: [u8; 32], pointer: u32, } }
For animation-type APCs, the name is 32 bytes, ASCII, zero-terminated, and padded with zeros/properly zeroed-out. The next two fields are 4 bytes in size each (u32?), and always zero (0).
For object-type APCs, the active field (u32) is always zero (0) or one (1), a Boolean. However, for object-type APCs with the parent role, they are always inactive (0). The name is also 32 bytes, ASCII, zero-terminated, and padded with zeros/properly zeroed-out. Finally, the pointer (u32) is always non-null/non-zero.
I haven't explored if there is any ordering to APCs, e.g. how parent APCs know which APCs are their children.
Animation references
If the animation references count was greater than zero, the animation references array is read. Each item is a 72 byte structure. Unlike other arrays, the first item is not zeroed out!
#![allow(unused)] fn main() { struct AnimRef { name: [u8; 64], unk64: u32, // always 0 unk68: u32, // always 0 } }
I'm not sure if the name field is actually 64 bytes long. Some values are properly zero-terminated at 32 bytes and beyond, but not all. Again, this is possibly a lack of zeroing out the memory. In any case, it's a zero-terminated, ASCII string. The next two fields are 4 bytes in size each (u32?), and always zero (0).
There's one animation reference per CALL_ANIMATION sequence event, and there may be duplicates to the same animation since multiple calls might needed.
Reset sequence
The reset sequence is read next, and is read unconditionally, i.e. every animation definition has a reset sequence - even the zeroed out first animation definition!
The reset sequence is special in that it always has the same name (RESET_SEQUENCE), and a separate reference to it is kept. Otherwise, it is largely the same as any other sequence:
#![allow(unused)] fn main() { struct SequenceDefinition { name: [u8; 32], flags: u32, // always 0 or 0x0303 unk36: [u8, 20], // always 0 pointer: u32, size: u32, } enum SequenceActivation: u32 { Initial = 0, OnCall = 3, } }
For any sequence, the name is 32 bytes long, ASCII, zero-terminated, and properly zeroed out.
The flags can either be zero (0) or 0x0303. This corresponds to the activation of either initial (0) or on call (3). But there are likely others we don't know about because they don't appear in the file.
The next 20 bytes (at offset 36) are unknown and always zero (0). Finally, the pointer (u32) and size (u32). If the size is zero (0), then the pointer will be zero/null, and no further data is read. This indicates an empty reset sequence. Otherwise, size bytes of sequence event data is read. I'll describe how to read sequence event data shortly.
For the reset sequence, the name will always be RESET_SEQUENCE. The flags will always be zero, an initial activation. It will always match the reset state in the animation definition.
Sequence definitions
If the sequence definitions count was greater than zero, the sequence definitions are read. Please see the reset sequence section for the sequence definitions structure.
Sequence events
Is this file not complicated enough yet? Sequence events will fix that. It starts easy. The size of the sequence event data (in bytes) is known from the sequence definition. Simply keep reading the events until that many bytes have been read. Each event starts with a header:
#![allow(unused)] fn main() { struct EventHeader { event_type: u8, start_offset: StartOffset, pad02: u16, // always 0 size: u32, start_time: f32, } enum StartOffset: u8 { Animation = 1, Sequence = 2, Event = 3, } }
The event type (u8) indicates just that. We'll get to these. The start offset (u8) can either be animation (1), sequence (2), or event (3). The explicit padding at offset 2 is always zero (0). The size indicates the size of this event's total data (including the header). The start time indicates the event's start time relative to the start offset/parent (probably).
There are 33 known event types, and they are described separately in sequence events. Fun story, these each require parsing.
Sequence events
Events by index
Events by name
Sequence events
#![allow(unused)] fn main() { struct EventHeader { event_type: u8, // could also be an enum start_offset: StartOffset, pad02: u16, // always 0 size: u32, start_time: f32, } enum StartOffset: u8 { Animation = 1, Sequence = 2, Event = 3, } }
The event type (u8) indicates just that, the type of the event, and therefore how to interpret the data following the header. The start offset (u8) can either be animation (1), sequence (2), or event (3). The explicit padding at offset 2 is always zero (0). The size indicates the size of this event's entire data (including the header). The start time indicates the event's start time relative to the start offset/parent (probably).
The event structures and their sizes specified in this document are all without the header, for convenience. Subtract 12 bytes (the size of the header) from the size in the header to get the event sizes specified.
Index lookups
Sequence events can refer to information in their associated animation definition, for example:
- Object3d nodes
- Sound nodes (dynamic sounds)
- Other nodes (just called nodes)
- Sounds (static sounds)
- Lights
- Puffers
Based on the packing of some structures and the general size of the arrays in GameZ, I assume node indices are 2 bytes/16 bits, so u16 or i16. We do see negative numbers, so I assume it's i16, leaving a maximum index of 32767 - still a lot larger than the usual array sizes.
As mentioned, there are negative numbers that seem to have special meanings. For example, if the reader file says INPUT_NODE, this is translated to the index -200.
#![allow(unused)] fn main() { const INPUT_NODE_INDEX: i16 = -200; }
It's unknown if this is allowed for all node indices, or only some.
Sound
Reader name: SOUND, Type: 1, Size: 16
Also called "static sound" in this project.
#![allow(unused)] fn main() { struct Sound { sound_index: i16, node_index: i16, translation: Vec3, } }
The sound index (i16) is used to look up the static sound in the animation definition. The node index (i16) is used to look up the parent/at node in the animation definition. The translation (Vec3) is presumably the sound's translation from the node.
Sound node
Reader name: SOUND_NODE, Type: 2, Size: 60
Also called "dynamic sound" in this project.
#![allow(unused)] fn main() { struct SoundNode { name: [u8; 32], unk32: u32, // always 1 flags: SoundNodeFlags, active_state: u32, // always 0 or 1 (bool) node_index: i16, pad46: u16, // always 0 translation: Vec3, } bitflags SoundNodeFlags: u32 { InheritTranslation = 1 << 1; // 0x2 } }
The sound node's name (32 bytes) is zero-terminated and zero padded. It's unclear why dynamic sounds aren't looked up by index, maybe this event creates a new node? The next field (u32) is always one (1). The flags field (u32) seems to be a bit field and is either zero (0) or two (2). The active state (u32) is either zero (0, false) or one (1, true). The node index (i16) is used to look up the parent/at node in the animation definition. The next field (u16) is padding and will always be zero (0). The translation (Vec3) is presumably the sound's translation from the node. If inherit translation flag (1 << 1 or 0x2) is unset, then the node index and the translation will be zero (0/0.0).
Light state
Reader name: LIGHT_STATE, Type: 4, Size: 120
#![allow(unused)] fn main() { struct LightState { name: [u8; 32], light_index: i16, pad34: u16, // always 0 flags: LightFlags, active_state: u32, // always 0 or 1 (bool) point_source: u32, // always 1 directional: u32, // always 0 or 1 (bool) saturated: u32, // always 0 or 1 (bool) subdivide: u32, // always 0 or 1 (bool) static: u32, // always 0 or 1 (bool) node_index: i32, translation: Vec3, rotation: Vec3, range_near: f32, range_far: f32, color: Color, ambient: f32, diffuse: f32, } // Also used for light nodes in GameZ bitflags LightFlags: u32 { // This flag never occurs in sequence events TranslationAbs = 1 << 0; // 0x001 Translation = 1 << 1; // 0x002 // This flag never occurs in sequence events Rotation = 1 << 2; // 0x004 Range = 1 << 3; // 0x008 Color = 1 << 4; // 0x010 Ambient = 1 << 5; // 0x020 Diffuse = 1 << 6; // 0x040 Directional = 1 << 7; // 0x080 Saturated = 1 << 8; // 0x100 Subdivide = 1 << 9; // 0x200 Static = 1 << 10; // 0x400 Inactive = 0; Default = TranslationAbs | Translation | Range | Directional | Saturated | Subdivide; } }
The light node's name (32 bytes) is zero-terminated and zero padded. The light node's index (i16) is used to look up the light in the animation definition. It's unclear why the light state contains both the light node's name and index. When looked up by index, that name matches the name in this structure. The next field (u16) is padding and will always be zero (0).
The light flags (u32) are also used for light nodes in GameZ, and indicate which further fields/states are valid and should be set. The TranslationAbs flag (1 << 0, 0x001) is never set in sequence events/in anim.zbd that we have.
The active state (u32) is always zero (0, false) or one (1, true). The point source field (u32) indicates whether the light is directed (0, never occurs) or a point source (1, always). The directional field (u32) is always zero (0, false) or one (1, true). If the directional flag (1 << 7, 0x080) is unset, this is always false. The saturated field (u32) is always zero (0, false) or one (1, true). If the saturated flag (1 << 8, 0x100) is unset, this is always false. The subdivide field (u32) is always zero (0, false) or one (1, true). If the subdivide flag (1 << 9, 0x200) is unset, this is always false. The static field (u32) is always zero (0, false) or one (1, true). If the static flag (1 << 10, 0x400) is unset, this is always false.
The node index (i32) is used to look up the parent/at node in the animation definition.
It's unclear why dynamic sounds aren't looked up by index, maybe this event creates a new node? The next field (u32) is always one (1). Inherit translation (u32) seems to be a bit field and is either zero (0) or two (2). The active state (u32) is either zero (0, false) or one (1, true).
The node index (i16) is used to look up the parent/at node in the animation definition. This is sometimes set to the special input node value. The next field (u16) is padding and will always be zero (0). The translation (Vec3) is presumably the sound's translation from the node. If the translation flag (1 << 1, 0x002) is unset, then both the node index and translation will be zero (0/0.0).
The rotation or direction (Vec3) is always zero (0.0), because the rotation flag (1 << 2, 0x004) is never set in sequence events/in anim.zbd that we have.
The near range (f32) and far range (f32) likely indicate the light's range. The near range is greater than or equal to zero (0.0), and the far range is greater than or equal to the near range. If the range flag (1 << 3, 0x008) is unset, then both are zero (0.0).
The colour (Color) is the RGB value of the light, and all values between zero (0.0) and one (1.0), inclusive of both. If the colour flag (1 << 4, 0x010) is unset, all values are zero (0.0). Finally, the ambient (f32) and diffuse (f32) control two aspects of lighting used in computer graphics. Both values are between zero (0.0, inclusive) and one (1.0, inclusive). If the ambient flag (1 << 5, 0x020) or diffuse flag (1 << 6, 0x040) are unset, the respective value will be zero (0.0).
Light animation
Reader name: LIGHT_ANIMATION, Type: 5, Size: 100
Object active state
Reader name: OBJECT_ACTIVE_STATE, Type: 6, Size: 8
Object translate state
Reader name: OBJECT_TRANSLATE_STATE, Type: 7, Size: 20
Object scale state
Reader name: OBJECT_SCALE_STATE, Type: 8, Size: 16
Object rotate state
Reader name: OBJECT_ROTATE_STATE, Type: 9, Size: 20
Object motion
Reader name: OBJECT_MOTION, Type: 10, Size: 320
Object motion from to
Reader name: OBJECT_MOTION_FROM_TO, Type: 11, Size: 132
Object motion SI script
Reader name: OBJECT_MOTION_SI_SCRIPT, Type: 12, Size: Variable, at least 24
Object opacity state
Reader name: OBJECT_OPACITY_STATE, Type: 13, Size: 12
Object opacity from to
Reader name: OBJECT_OPACITY_FROM_TO, Type: 14, Size: 24
Object add child
Reader name: OBJECT_ADD_CHILD, Type: 15, Size: 4
Object cycle texture
Reader name: OBJECT_CYCLE_TEXTURE, Type: 17, Size: 8
Object connector
Reader name: OBJECT_CONNECTOR, Type: 18, Size: 76
Call object connector
Reader name: CALL_OBJECT_CONNECTOR, Type: 19, Size: 68
Call sequence
Reader name: CALL_SEQUENCE, Type: 22, Size: 36
Stop sequence
Reader name: STOP_SEQUENCE, Type: 23, Size: 36
Call animation
Reader name: CALL_ANIMATION, Type: 24, Size: 68
Stop animation
Reader name: STOP_ANIMATION, Type: 25, Size: 36
Reset animation
Reader name: RESET_ANIMATION, Type: 26, Size: 36
Invalidate animation
Reader name: INVALIDATE_ANIMATION, Type: 27, Size: 36
Fog state
Reader name: FOG_STATE, Type: 28, Size: 68
Loop
Reader name: LOOP, Type: 30, Size: 8
If
Reader name: IF, Type: 31, Size: 12
Else
Reader name: ELSE, Type: 32, Size: 0
Elseif
Reader name: ELSEIF, Type: 33, Size: 12
Endif
Reader name: ENDIF, Type: 34, Size: 0
Callback
Reader name: CALLBACK, Type: 35, Size: 4
FBFX color from to
Reader name: FBFX_COLOR_FROM_TO, Type: 36, Size: 52
Presumably, FBFX stands for "frame buffer effect".
Detonate weapon
Reader name: DETONATE_WEAPON, Type: 41, Size: 24
Puffer state
Reader name: PUFFER_STATE, Type: 42, Size: 580
#![allow(unused)] fn main() { struct PufferState { name: [u8; 32], puffer_index: i16, pad34: u16, // always 0 flags: PufferStateFlags, active_state: i32, node_index: u32, translation: Vec3, local_velocity: Vec3, world_velocity: Vec3, min_random_velocity: Vec3, max_random_velocity: Vec3, world_acceleration: Vec3, interval_type: u32, interval_value: f32, size_range: Vec2, lifetime_range: Vec2, start_age_range: Vec2, deviation_distance: f32, unk156: f32, // always 0.0 unk160: f32, // always 0.0 fade_range: Vec2, friction: f32, unk176: u32, // always 0 unk180: u32, // always 0 unk184: u32, // always 0 unk188: u32, // always 0 tex192: [u8; 36], tex228: [u8; 36], tex264: [u8; 36], tex300: [u8; 36], tex336: [u8; 36], tex372: [u8; 36], unk408: [u8; 120], // always 0 unk528: u32, unk532: u32, // always 0 unk536: f32, unk540: f32, growth_factor: f32, unk548: [u8; 32], // always 0 } bitflags PufferStateFlags: u32 { // this might not be right? Translate = 1 << 0; // 0x00001 GrowthFactor = 1 << 1; // 0x00002 // this might not be right? State = 1 << 2; // 0x00004 LocalVelocity = 1 << 3; // 0x00008 WorldVelocity = 1 << 4; // 0x00010 MinRandomVelocity = 1 << 5; // 0x00020 MaxRandomVelocity = 1 << 6; // 0x00040 IntervalType = 1 << 7; // 0x00080 // this might not be right? IntervalValue = 1 << 8; // 0x00100 SizeRange = 1 << 9; // 0x00200 LifetimeRange = 1 << 10; // 0x00400 DeviationDistance = 1 << 11; // 0x00800 FadeRange = 1 << 12; // 0x01000 Active = 1 << 13; // 0x02000 CycleTexture = 1 << 14; // 0x04000 StartAgeRange = 1 << 15; // 0x08000 WorldAcceleration = 1 << 16; // 0x10000 Friction = 1 << 17; // 0x20000 Inactive = 0; } }
The puffer's name (32 bytes) is zero-terminated and zero padded. The puffer's index (i16) is used to look up the puffer in the animation definition. It's unclear why the puffer state contains both the puffer's name and index. When looked up by index, that name matches the name in this structure. The next field (u16) is padding and will always be zero (0).
The puffer state's flags (u32) indicate which further fields/states are valid and should be set. If the state flag (1 << 3, 0x00008) is unset, then no other flags are set in the sequence events/in anim.zbd that we have. This seems to indicate whether the puffer is disabled/inactive. At least, that's the best guess. However, there's also an active flag and an active state, which seems to be slightly different.
The active or lifetime state (i32) seems to allow for a range of values. If the active flag is set, then the active state will be greater than or equal to one (1), and less than or equal to five (5). If the active flag (1 << 13, 0x02000) is unset, then the active state is always negative one (-1).
TODO
Text reader files
Text reader files have the file extension .zrd, which could stand for Zipper Reader. Until 2022, I only knew of binary reader files. However, there exist text reader files, for example DefaultCtlConfig.zrd.
Investigation (MW3)
Although it was assumed the reader files were Lisp-like from the binary reader files, the text reader files confirm this:
(
⇥ KEYS (
⇥ ⇥ (CMD_ALPHASTRIKE ⇥ keya(0x9c) ⇥ joybtn(0x6))
⇥ ⇥ (CMD_AMS_TOGGLE ⇥ keya(0x1e))
...
⇥ )
⇥ AXES (
⇥ ⇥ (Throttle ⇥ joystick(Z) ⇥ slope(-0.500000) ⇥ intercept(0.500000) ⇥ deadzone(0.050000))
⇥ ⇥ (Twist ⇥ joystick(Rz) ⇥ slope(-1.000000) ⇥ intercept(0.000000) ⇥ deadzone(0.000000))
⇥ ⇥ (Pitch ⇥ joystick(Y) ⇥ slope(1.000000) ⇥ intercept(0.000000) ⇥ deadzone(0.000000))
⇥ ⇥ (LR ⇥ joystick(X) ⇥ slope(-1.000000) ⇥ intercept(0.000000) ⇥ deadzone(0.000000))
⇥ )
)
Note that the whitespace delimiter used is a tab (indicated as ⇥ above).
There are a lot of interesting quirks with this lisp dialect. First, the whitespace delimiters are definitely tab, carriage return (CR), and line feed (LF), i.e. CR+LF don't seem to have a syntactic value. This is not unusual, but it isn't clear if a space is a valid delimiter. This also ties into the fact that strings don't seem to be quoted.
From the binary reader files, we know there are only four data types:
- Integers (i32)
- Floating-point numbers (f32, "floats")
- Strings
- Lists
Interestingly, the text reader files hint that at least mentally, there were more. For example, it seems like strings are always upper-case, and lower-case strings are symbols. This also leads to a concept of a "function" data type in the text reader, for example joybtn(0x6). In other Lisps, this would've been written as (joybtn 0x6). Also, maps/dictionaries are simply lists with implicit key-value pairs.
We don't know how the text reader files are precisely lexed. If I had to guess from binary reader files, the example above would be expressed in pseudo-JSON as follows:
[
"KEYS",
[
["CMD_ALPHASTRIKE", "keya", [0x9c], "joybtn", [0x6]],
["CMD_AMS_TOGGLE", "keya", [0x1e]],
...
],
"AXES",
[
["Throttle", "joystick", ["Z"], "slope", [-0.5], "intercept", [0.5], "deadzone", [0.05]],
["Twist", "joystick", ["Rz"], "slope", [-1.0], "intercept", [0.0], "deadzone", [0.0]],
["Pitch", "joystick", ["Y"], "slope", [1.0], "intercept", [0.0], "deadzone", [0.0]],
["LR", "joystick", ["X"], "slope", [-1.0], "intercept", [0.0], "deadzone", [0.0]]
]
]
I believe the engine has an implicit schema, in that it tries to find string values by index, and then any information/arguments it needs are retrieved from index + 1.
There are still questions. For example, what happens if we mess with the order of "AXES"? Presumably when parsing, it looks at list index 0 to figure out what to put where in already existing data structures in the engine.
Control configuration
The MechWarrior 3 engine uses DirectInput for controls. This also matches the key codes (keya) in the DefaultCtlConfig.zrd, they are DirectInput key codes. Below is a converter:
Beginner's guide to hex viewing
You'll need a hex viewer or editor. On Windows, I strongly recommend HxD. This guide is specifically for 32-bit inspection, so 64-bit values are unlikely.
Endianness
Endianness is an important concept, but complicated. I'll cover the minimum necessary. x86 CPUs all use little endian. This means if you have a 32-bit value, for example 0xDEADBEEF, it is stored in memory as [0xEF, 0xBE, 0xAD, 0xDE].
0xDEADBEEF
| | | | (mem)
| | | +- 0xEF
| | +--- 0xBE
| +----- 0xAD
+------- 0xDE
This is slightly unintuitive, but luckily, most hex viewers will be able to display the decoded values.
Integers
Integers can be either signed or unsigned. Unsigned integers can be zero, or positive. Signed integers can be negative, zero, or positive. Zero has no sign (there is only 0, not +0 and -0). Both signed and unsigned integers have a size; generally 8, 16, 32, or 64 bits (1, 2, 4, or 8 bytes).
Unsigned
| Size | Min (dec) | Min (hex) | Max (dec) | Max (hex) |
|---|---|---|---|---|
| 8 bit | 0 | 0x00 | 255 | 0xFF |
| 16 bits | 0 | 0x0000 | 65535 | 0xFFFF |
| 32 bits | 0 | 0x00000000 | 4294967295 | 0xFFFFFFFF |
Signed
| Size | Min (dec) | Min (hex) | -1 (hex) | 0 (hex) | Max (dec) | Max (hex) |
|---|---|---|---|---|---|---|
| 8 bit | -128 | 0x80 | 0xFF | 0x00 | 127 | 0x7F |
| 16 bits | -32768 | 0x8000 | 0xFFFF | 0x0000 | 32767 | 0x7FFF |
| 32 bits | -2147483648 | 0x80000000 | 0xFFFFFFFF | 0x00000000 | 2147483647 | 0x7FFFFFFF |
As you can see, for signed integers, the sign is encoded in the top-most bit (most significant bit or MSB). The negative values are also not intuitive, since they are encoded in two's complement. It's helpful to know this; but again most hex viewers can decode signed integers.
In general, unless you see an obviously signed value (for example, anything above 0x80000000 where > 2147483647 would be too large), it's impossible to tell if the type is signed or unsigned from the reverse engineering. Also, due to little endian storage, if you see the bytes [0x7F, 0x00, 0x00, 0x00] (7F000000), you cannot tell if this is a) a 32-bit integer with the value 127, b) two 16-bit integers with the values 127 and 0, or even c) four 8-bit integers with the values 127, 0, 0, 0.
For this reason, if you write any parsing code, you may want to strictly check the bounds of values. This then makes it easier to catch unexpected values earlier.
Quiz
The quiz001 file contains some values, all of the same type. Can you tell what type of integer (and therefore how many they are), and what the values are?
There were ten 32-bit signed integers: 111, 9999, 10, 2000, 10, -200, 10, 0, 1, 100000
Reveal answer
Floating point values
Floating point values basically encode a number in scientific notation, see IEEE 754. The information of a signed bit, the exponent, and the fraction is encoded into either 32 or 64 bits (called single or double precision, respectively). For example, a 32-bit floating point value is packed as follows:
0 01111100 01000000000000000000000 = 0.15625
| | | | |
| exponent fraction
sign
A normal human can't be expected to decode this; the hex viewer will help here also. However, with a small amount of practice, you can recognise some values.
- 1.0 is 0x3F80000
- -1.0 is 0xBF800000
- 10.0 is 0x41200000
- -10.0 is 0xC1200000
- 100.0 is 0x42c80000
- -100.0 is 0xC2C80000
However, 0.0 is 0x00000000, and so indistinguishable from an integer! In this documentation, I try to denote floating point values with a decimal point and at least one place to distinguish them from integers, e.g. 10 is an integer, 10.0 is a float.
Quiz
The quiz002 file contains a mix of 32-bit integers and 32-bit floats. Can you tell what the values are?
The values were 9999, 0.5, -0.5, 1, -1, 200, 200.0, and indeterminate (could have been 0/integer or 0.0/float).
Reveal answer
Strings
Strings in C are basically arrays of ASCII/ANSI characters. Each character has a numeric value (see Wikipedia for an ASCII table). This is why a lot of hex viewers also show an ASCII view next to the hex view, and simply skip non-printable characters. Because each character is a byte, you do not need to worry about endianness for ASCII strings:
b"Hello world" = 48 65 6c 6c 6f 20 77 6f 72 6c 64
Strings in C are usually terminated with a null or zero character (\0, 0xFF); this is called zero-terminated. So "Hello world" would actually be 48656c6c6f20776f726c6400.
Strings are either stored as fixed length or with a known length encoded before the string. Fixed length strings are usually padded with zeros, so encoding "Hello world" as a 16 length string is:
b"Hello world\0\0\0\0\0" = 48656c6c6f20776f726c640000000000
However, the padding can also be garbage if the programmer forgets to zero the memory, so this is also "Hello world": 48656c6c6f20776f726c6400DEADBEEF (note this is still zero-terminated). For a known-length string, "Hello world" could be either:
# Zero terminated
b"Hello world\0" = length 12 = 0c000000 48656c6c6f20776f726c6400
# (b'\x0c\x00\x00\x00Hello world\x00' in Python)
# Not terminated
b"Hello world" = length 11 = 0b000000 48656c6c6f20776f726c64
# (b'\x0b\x00\x00\x00Hello world' in Python)
Assuming the length is encoded as a 32-bit integer.
Quiz
The quiz003 file contains several strings. They are separated by DEADBEEFDEADBEEFDEADBEEF. Can you tell what type of strings they are, and what the values were?
Reveal answer
0xDE, 0xAD, 0xBE, 0xEF)
Structures
This is a vast oversimplification, but structures basically describe a view/block of memory, that makes it easier to work with in code. They are usually collection of fields, although the field names are identifiers in the source code only, and not present in the actual memory. For example, given this C structure:
struct Foo {
uint32_t a;
float a;
}
Then Foo { a = 100, b = 100.0 } would be encoded as:
64000000 0000c842
When reverse engineering, the structure definitions is what we're usually trying to recover. I'll be using pseudo-Rust code to describe structures, as in the rest of the documentation (as opposed to C code).
Quiz
Reverse engineer the structure of quiz004. All data types are 32-bit/32-bit aligned.
The structure was:
And the value was Reveal answer
#![allow(unused)]
fn main() {
struct Quiz010 {
a: f32,
b: [u8; 16],
c: i32, // or u32
}
}Quiz004 { a: 1.5, b: "You can do it", c: 8888}.